
Research papers come out far too rapidly for anyone to read them all, especially in the field of machine learning, which now affects (and produces papers in) practically every industry and company. This column aims to collect the most relevant recent discoveries and papers — particularly in but not limited to artificial intelligence — and explain why they matter.
A number of recently published research projects have used machine learning to attempt to better understand or predict these phenomena.
This week has a bit more “basic research” than consumer applications. Machine learning can be applied to advantage in many ways users benefit from, but it’s also transformative in areas like seismology and biology, where enormous backlogs of data can be leveraged to train AI models or as raw material to be mined for insights.
Inside earthshakers
We’re surrounded by natural phenomena that we don’t really understand — obviously we know where earthquakes and storms come from, but how exactly do they propagate? What secondary effects are there if you cross-reference different measurements? How far ahead can these things be predicted?
A number of recently published research projects have used machine learning to attempt to better understand or predict these phenomena. With decades of data available to draw from, there are insights to be gained across the board this way — if the seismologists, meteorologists and geologists interested in doing so can obtain the funding and expertise to do so.
The most recent discovery, made by researchers at Los Alamos National Labs, uses a new source of data as well as ML to document previously unobserved behavior along faults during “slow quakes.” Using synthetic aperture radar captured from orbit, which can see through cloud cover and at night to give accurate, regular imaging of the shape of the ground, the team was able to directly observe “rupture propagation” for the first time, along the North Anatolian Fault in Turkey.
“The deep-learning approach we developed makes it possible to automatically detect the small and transient deformation that occurs on faults with unprecedented resolution, paving the way for a systematic study of the interplay between slow and regular earthquakes, at a global scale,” said Los Alamos geophysicist Bertrand Rouet-Leduc.
Another effort, which has been ongoing for a few years now at Stanford, helps Earth science researcher Mostafa Mousavi deal with the signal-to-noise problem with seismic data. Poring over data being analyzed by old software for the billionth time one day, he felt there had to be better way and has spent years working on various methods. The most recent is a way of teasing out evidence of tiny earthquakes that went unnoticed but still left a record in the data.
The “Earthquake Transformer” (named after a machine-learning technique, not the robots) was trained on years of hand-labeled seismographic data. When tested on readings collected during Japan’s magnitude 6.6 Tottori earthquake, it isolated 21,092 separate events, more than twice what people had found in their original inspection — and using data from less than half of the stations that recorded the quake.

Image Credits: Stanford University
The tool won’t predict earthquakes on its own, but better understanding the true and full nature of the phenomena means we might be able to by other means. “By improving our ability to detect and locate these very small earthquakes, we can get a clearer view of how earthquakes interact or spread out along the fault, how they get started, even how they stop,” said co-author Gregory Beroza.
When “good enough” is better
Another famously difficult-to-predict phenomenon is, of course, the weather. One of the challenges there is the sheer amount of data involved in doing so. A meteorologist can look at the nearby fronts and readings and make a good guess about the next few days, but making long-term predictions is another matter, often involving years of trends coming together in incredibly complex systems.
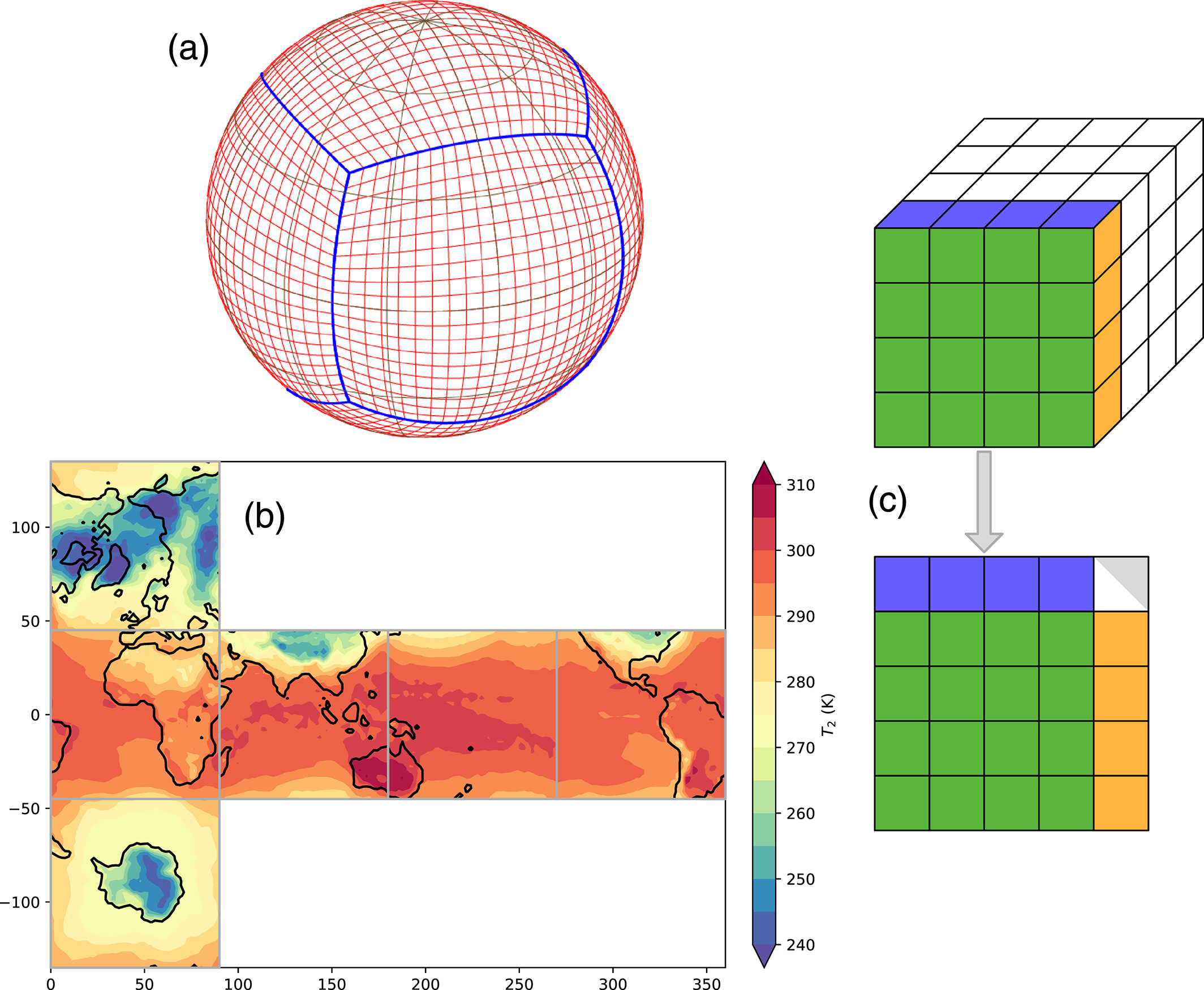
Image showing how the globe is divided into easier geometrical units for simulation by the UW system. Image Credits: Weyn et al./UW
A team at the University of Washington has cut the Gordian knot in a way, or at least given it a good whacking, by lowering their sights a little and letting machine learning do what it does best. They trained a model on 40 years of weather data with no info about physics or the underlying systems at work and found that while it’s not nearly as good as top-tier systems in making forecasts, it can make “good enough” predictions with a fraction of the computing resources.
That may make it a poor choice for a weekly forecast, but the speed means that meteorologists can run many simulations in the time it would normally take to do one, covering more bases and considering more edge cases. That’s useful in things like hurricane prediction. Right now the model is still very much in development but the approach seems highly promising (if not destined for consumer use).
Another area where machine models excel in performing “good enough” versions of tedious work is in turning one kind of imagery into another. We see it in fun things like turning sketches into monsters, or turning photos into paintings, but they all demonstrate the same capability of quickly turning data of one kind into another.
A rather esoteric branch of this problem involves turning 2D scans of bodies and organs into 3D imagery. Say you’re testing a drug that’s meant to stop infections from swelling the pancreas. When you scan an animal to find out whether it’s working or not, you need to figure out from the scan where the pancreas is compared to the other organs, how much space it’s taking up and so on. This can be a time-consuming, error-prone process.
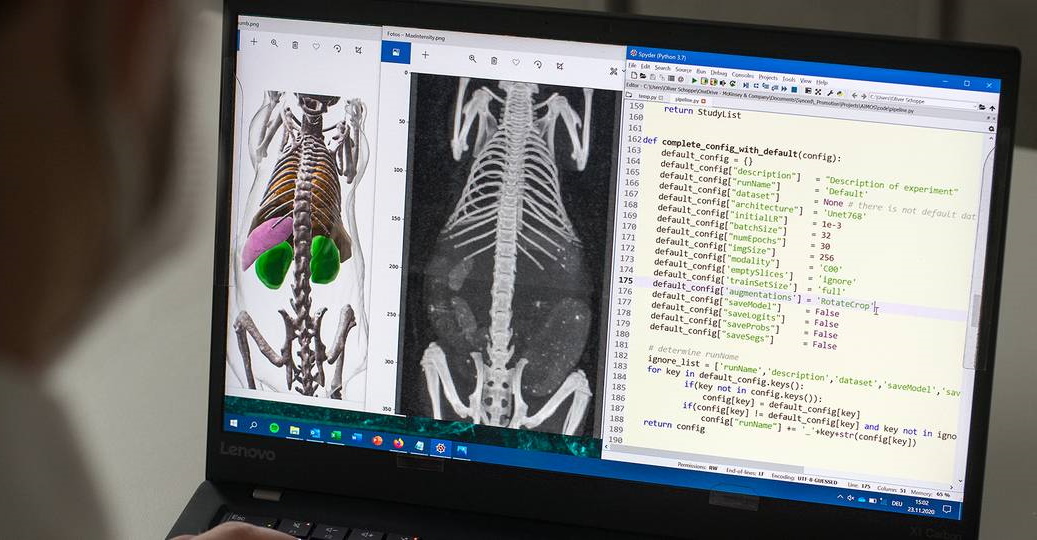
Image Credits: Astrid Eckert/TUM
A new bit of software from the Technical University of Munich automates this, letting an AI estimate the positions and sizes of the bones and organs. “We only needed around 10 whole-body scans before the software was able to successfully analyze the image data on its own — and within a matter of seconds. It takes a human hours to do this,” said TUM researcher Oliver Schoppe. The resulting estimates were even more accurate than human work. The paper was published in the journal Nature Communications.
The limits of the black box
In all these examples, AI is effective and useful, but the processes by which it reaches its results are not very well-documented. When you’re reconstructing mouse organs that’s not so important, but for an algorithm determining something more sensitive it’s starting to be crucial, in order to show there’s no bias or corruption in the process.
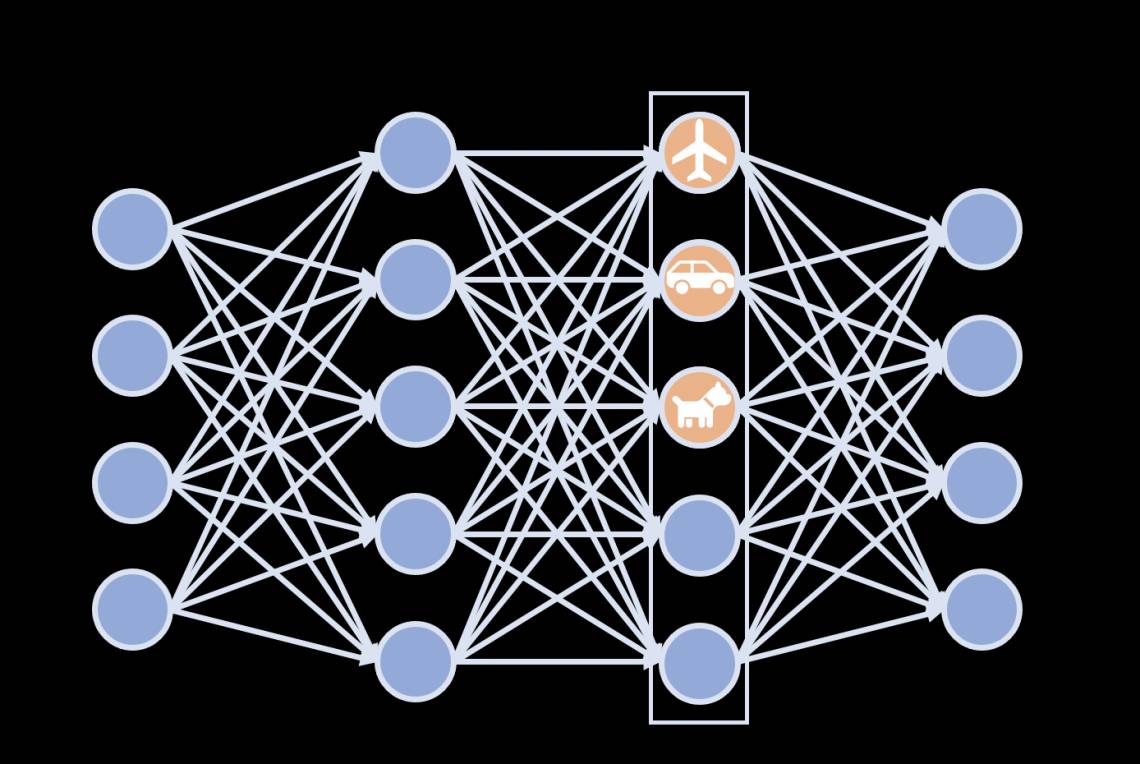
Image Credits: Stanford University
Duke researchers are working on a way for an AI to show its work, so to speak, by making it clear what concepts have come into play in its determinations. For instance if a computer-vision algorithm looks at a photo and determines it’s a bedroom — what tipped it off? Was it the bed? The sheets specifically? Perhaps the nightstand with an alarm clock on it? Or is there something more subtle at play? The obvious solution (the bed!) may not be the correct one, as the famous example of the “sheep in a grassy field” shows (an AI described grassy scenes as having sheep in them even if they didn’t, because it understood grassy as including sheep).
Using the Duke method, the AI would not just report its final determination, but what parts of its “memory” were activated in the process of reaching it. That way if there are red herrings in there, or problematic leaps of computer logic, they will be honestly reported alongside the final product.
Lastly, some experts think that, black box or no, there ought to be hard limits on what machine learning is used for. EPFL’s Bryan Ford explained that there are fundamental shortcomings to AIs that make them unsuitable for, say, creating policy.
“Matters of policy in governing humans must remain a domain reserved strictly for humans,” he said at the Governance of and by Digital Technology virtual conference. “Because machine-learning algorithms learn from data sets that represent historical experience, AI-driven policy is fundamentally constrained by the assumption that our past represents the right, best or only viable basis on which to make decisions about the future. Yet we know that all past and present societies are highly imperfect so to have any hope of genuinely improving our societies, governance must be visionary and forward looking.”
Stuart Russell, an influential researcher in the field for decades and author of an interesting book on the topic (I interviewed him earlier this year), points out that practically every AI you use treats you as the product as well as the consumer:
“There is already AI from 50 different corporate representatives sitting in your pocket stealing your information, and your money, as fast as it can, and there’s nobody in your phone who actually works for you. Could we rearrange that so that the software in your phone actually works for you and negotiates with these other entities to keep all of your data private?”
At the very least it can’t hurt to try.