
Robin.io, a cloud-native application and data management solution with enterprise customers like USAA, Sabre, SAP, Palo Alto Networks and Rakuten Mobile, today announced the launch of its new free(-mium) version of its service, in addition to a major update to the core of its tool.
Robin.io promises that it brings cloud-native data management capabilities to containerized applications with support for standard operations like backup and recovery, snapshots, rollbacks and more. It does all of that while offering bare-metal performance and support for all major clouds. The service is essentially agnostic to the actual database being used and offers support for the likes of PostgreSQL, MySQL, MongoDB, Redis, MariaDB, Cassandra, Elasticsearch and others.
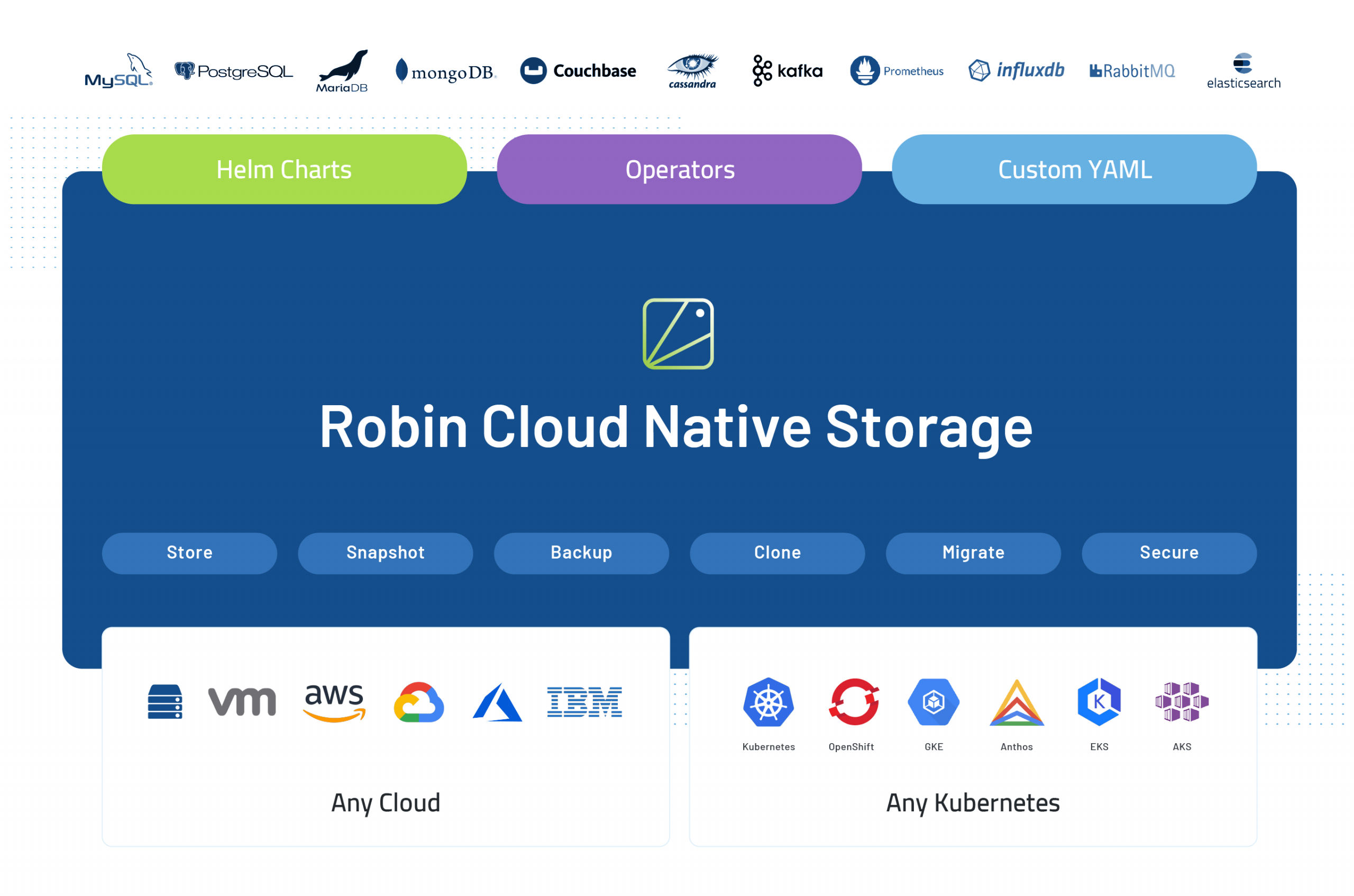
Image Credits: Robin.io
“Robin Cloud Native Storage works with any workload on any Kubernetes-based platform and on any cloud,” said Robin founder and CEO Partha Seetala. “With capabilities for storing, taking snapshots, backing up, cloning, migrating and securing data — all with the simplest of commands — Robin Cloud Native Storage offers developers and DevOps teams a super simple yet highly performant tool for quickly deploying and managing their enterprise workloads on Kubernetes.”
The new free version lets teams manage up to 5 nodes and 5TB of storage. The promise here is that this a free-for-life offering and the company obviously expects that it allows enterprises to get a feel for the service and then upgrade to its paid enterprise plans over time.
Talking about those enterprise plans, the company also today announced that it is moving to a consumption-based pricing plan, starting at $0.42 per node-hour (though it also offers annual subscriptions). The enterprise plan includes 24×7 support and doesn’t limit the number of nodes or storage capacity.
Among the new features to Robin’s core storage service are data management support for Helm Charts (where Helm is the Kubernetes package manager), the ability to specify where exactly the data should reside (which is mostly meant to keep it close to the compute resources) and affinity policies that ensure availability for stateful applications that rely on distributed databases and data platforms.