
What if you could mix and match different tracks from your favorite artists, or create new ones on your own with their voices?
This could become a reality sooner than later, as AI models similar to the ones used to create computer-generated art images and embed deepfakes in videos are being increasingly applied to music.
The use of algorithms to create music is not new. Researchers used computer programs to generate piano sheet music as far back as the 1950s, and musicians from that era such as Iannis Xenakis and Gottfried Koenig even used them to compose their own music.
What has changed are the improvements in generative algorithms, which first gained popularity back in 2014, coupled with large amounts of compute power that are increasingly changing what computers can do with music today.
OpenAI recently released a project called JukeBox, which uses the complex raw audio form to help create entirely new music tracks based on a person’s choice of genre, artist and lyrics. Meanwhile, tools such as Amazon’s AWS DeepComposer and ones released by the Google Magenta project are helping to democratize the ability for developers to experiment with deep learning algorithms and music.
With respect to commercial use, startups such as Amper Music, which lets users create customized, royalty-free music, are seeing businesses adopt computer-generated pieces for a range of use cases surrounding background tracks for videos, and record labels have started to play around with music written by AI.
As the technology and quality of computer-generated music matures, it will likely bring a lot of changes to the media industry from individual artists to record labels to music streaming companies, and present a slew of legal questions over computer-generated music rights.
Understanding the early market for computer-generated music
Early adopters of computer-generated music have included companies interested in replacing stock music with customized, royalty-free music, with uses ranging from marketing videos to background clips for app videos.
Amper Music, which was co-founded by a trio of music composers and has raised over $9 million from investors, including Horizons Ventures and Two Sigma Ventures, offers a music generation platform that lets businesses generate new tracks based on characteristics such as style, length and structure. Its customers include companies like Reuters, which has partnered with Amper, to enable publishers on their Reuters Connect platform to add AI-based background music while they edit videos.
Jukedeck, a competing U.K.-based AI startup that had built a custom music generation platform — and won the TechCrunch Disrupt London Battlefield competition in 2015 — was acquired last year by ByteDance, owner of TikTok. The move was likely tied to the music streaming service that TikTok has been quietly building, as reported earlier this year, but also helps TikTok bypass licensing fees it has been paying for background music used by users on its app.
Record labels have also started to get involved with computer-generated music. Warner Music Group signed a deal last year with an early-stage audio startup called Endel, through which Warner is using 600 tracks across 20 albums developed by Endel’s technology. Snafu, a new record label company, is using AI to evaluate artists’ music in the hopes of better predicting which artists are likely to create the next big hit. These represent early forays for record labels, but hint at a future where they could pay for computer-generated music and use algorithms to evaluate artists’ works.
When it comes to music-streaming services like Spotify and Apple Music, computer-generated music isn’t at a point yet where it can compete with the thousands of high-quality tracks being added daily by artists, and consumer interest for such music has yet to develop. Instead, music streaming companies are using algorithms to offer up new track suggestions based on users’ preferences and moods.
Spotify has “Discovery Weekly,” which gives users a weekly curated list of songs based on their existing playlists and what other users with similar preferences listen to. Apple, which acquired Shazam back in 2017, makes it possible for Apple Music users to pick a song and discover similar songs based on its mood with its “Genius Playlist” feature.
The current usage of computer-generated music is still in its early stages, and more technology innovation is required to improve the quality of computer-generated music to lead to wider adoption in the media industry.
Advances in deep learning are enabling more control over music creation
Generative algorithms such as General Adversarial Networks (GANs) have shown impressive results in generating text, speech and images over the last few years. They have recently begun to show impressive results in the music domain, as well, where a number of diverse approaches are being undertaken at a growing pace.
One of the approaches has involved researchers using generative algorithms to symbolically generate music by analyzing music at the note level. Such an approach involves capturing the timing, pitch, velocity and instrument of each note to be played, and doesn’t present data complexity as it treats the note as opposed to more granular numerical representations of the sounds as a base unit of analysis. A drawback of this approach, however, is that it can limit the generative capability to a finite sequence of notes or set of instruments.
Nonsymbolic approaches have also been undertaken, such as the use of raw audio directly to learn and create new pieces. The raw audio form holds more information than note-level data, resulting in a level of complexity that makes it difficult for a system to generate music for longer periods of time. The raw audio form, however, enables a system to capture the nuances of the human voice, such as the timbres and dynamics, which are lost when music is processed at the note level.
OpenAI’s recent work on JukeBox uses generative models to create high-fidelity music in the raw audio form, and deals with its complexity with a novel neural network architecture that uses encoders and decoders to reduce its dimensionality.
The system begins by first converting the raw audio to compressed audio, using Convolutional Neural Networks (CNNs) to learn the encoding of transforming the audio from the raw version to a lower dimensional compressed version.
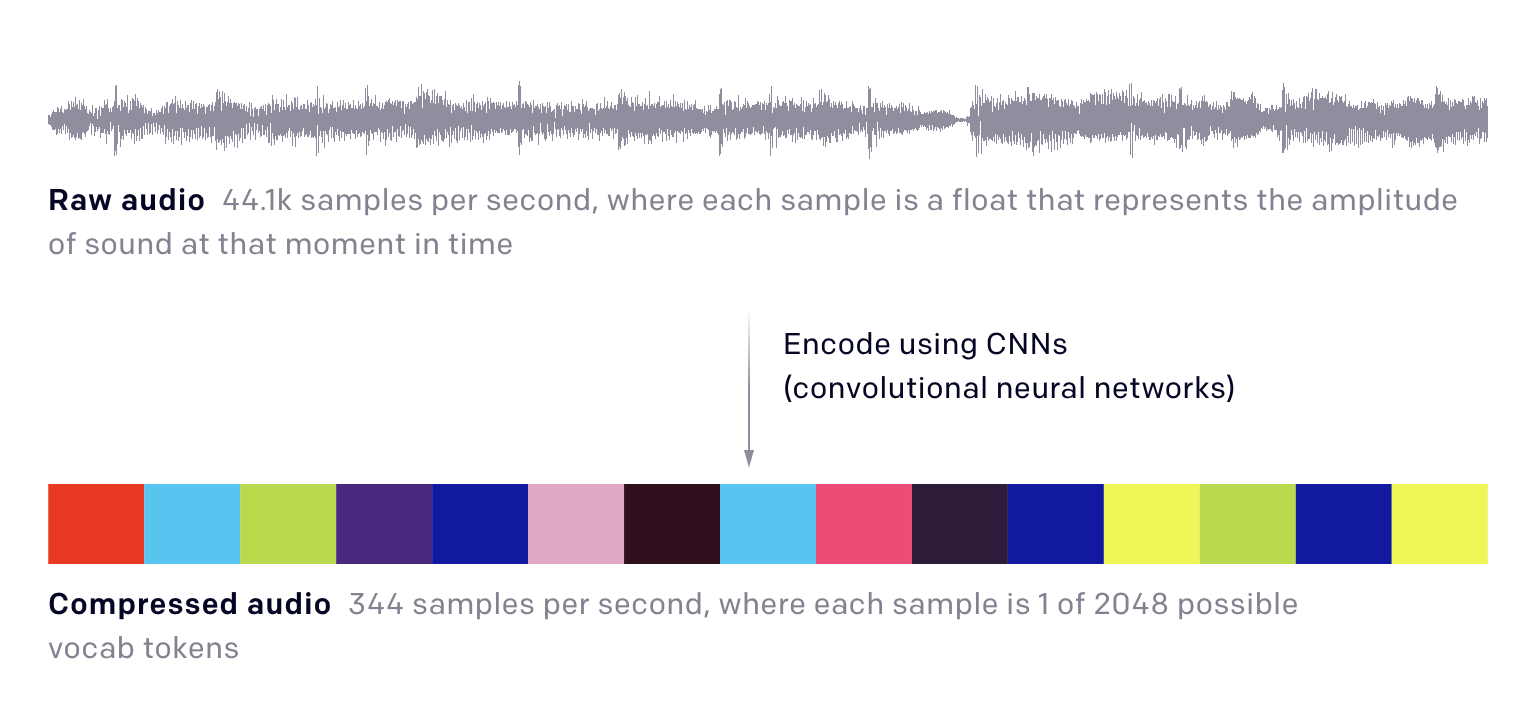
Source: OpenAI
The compressed audio is converted to a novel compressed audio, using the transformer network that is learned. This step adds the “novel patterns” that help generate the new music ultimately.
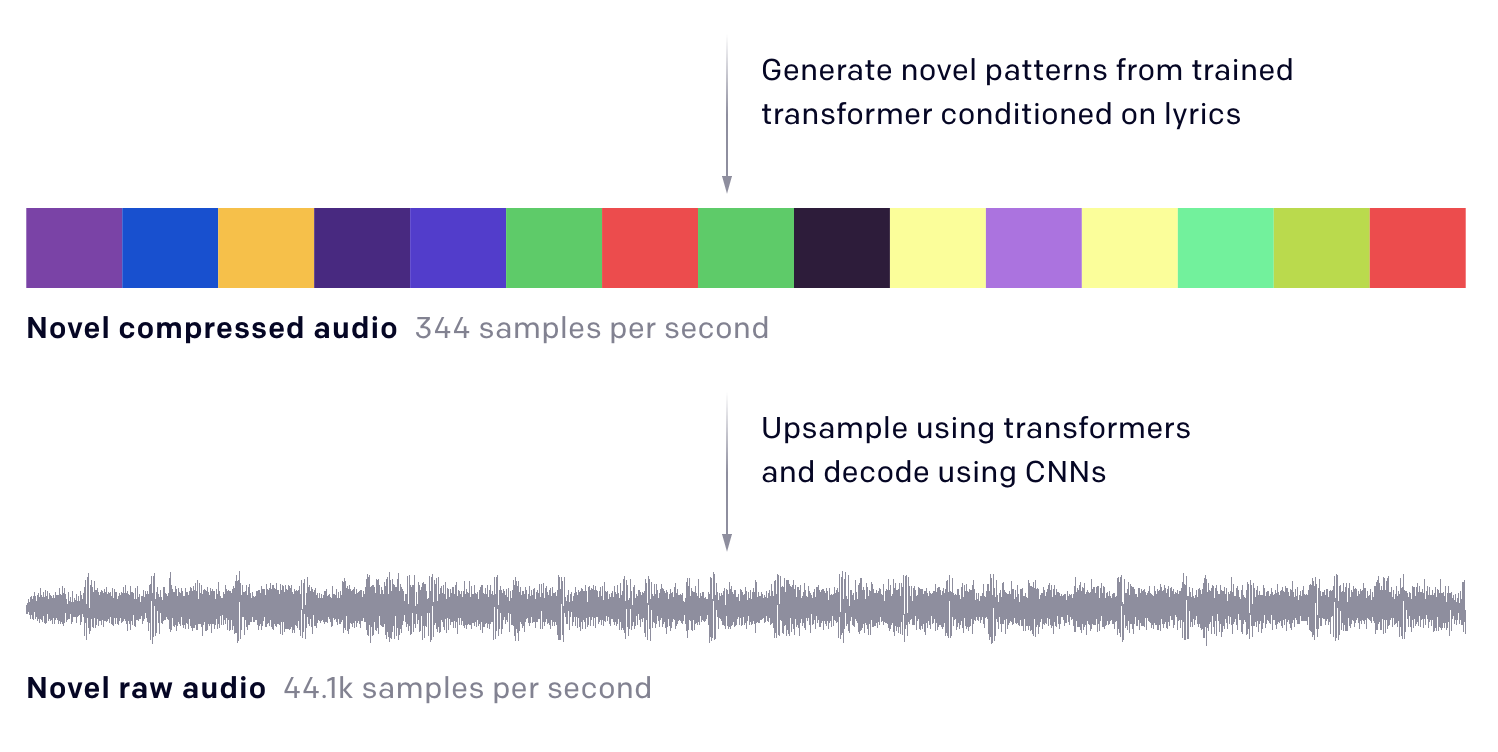
Source: OpenAI
The novel compressed audio is finally converted to the novel audio in its raw audio form, using CNNs to learn the decoding of transforming the audio from the compressed version to a higher dimensional raw version.
The training for JukeBox involved 1.2 million songs curated from the web, about half of which were in English. The resulting system is able to take a music genre, artist and lyrics as input, and create a new music sample. Interestingly, OpenAI’s team used encoder CNNs with different compression rates to see how it affected the music sample quality, and the differences in sound quality are apparent in the examples they share.
The use of generative models in JukeBox is particularly compelling given the interplay of genre, artist and lyrics that are involved in creating the new music samples. Moreover, the system also has a trained network that helps match the vocals to word-level alignment in the lyrics. Some limitations of the work involve the noise introduced by the encoding and decoding, given the complexity of the raw audio data.
Beyond OpenAI’s work, application of deep learning techniques to music is increasing our understanding of various factors such as how audio data should be processed, which neural network architectures work well, and how to model variables such as music genre and style.
Projects such as Amazon’s AWS DeepComposer and Google Magenta are providing developers a platform to experiment with deep learning algorithms and music. When the ImageNet database of 14 million hand-annotated images was made public back in 2010, it led to a marked rise in efforts toward developing novel deep learning approaches for identifying objects in and classifying images. A similar interest in analyzing music stemming from readily available tools such as these would greatly help the pace of innovation.
Amazon’s AWS DeepComposer features a virtual keyboard that users can use to create a melody and then use a generative model to transform the music into a modified track. It lets them use generative model architectures built with Amazon SageMaker, in addition to providing various pre-trained models by genre. It further makes it easy for users to upload developed tracks directly to SoundCloud.
Meanwhile, Google Magenta is a research project that explores ML applications for both art and music. On the music front, their Magenta Studio platform allows users to generate new music, based on Magenta’s open source tools and models. They have further developed the NSynth (Neural Synthesizer) algorithm, which uses deep learning to learn the characteristics of sound at an individual sample level, and then creates new sounds based on that. The Nsynth algorithm can be experimented with using the physical interface NSynth Super, which enables musicians to explore over 100,000 sounds. The open source version of its prototype is available for download on GitHub.
What does the future of computer-generated music look like?
The capabilities in editing and creating music with software are still in their early stages, but the coming years will likely see continued improvement in the quality and diversity of computer-generated music.
Improvements in computer-generated music will spur technology companies that specialize in different ways of using AI to generate music, beyond early entrants such as Amper and Endel. Such companies could serve as independent artists, providing clients such as record labels with certain types of music, or provide music generation capabilities as a platform to media companies or individual artists. There are a number of additional markets, ranging from gaming to ads, which would benefit from better custom music options as well.
Record labels will become more active in signing on computer-generated music. This could involve partnering with companies producing computer-generated music such Warner’s deal with Endel, but could also involve partnering with independent artists who amplify their music with software that provides music editing capabilities. The quality of the music, relative to human artists, will be a key factor, but computer-generated music also offers record labels a way to obtain large amounts of music in limited time. When it comes to evaluation of artists’ works, it’s possible record labels may use AI to evaluate music pieces, but such approaches typically require large amounts of data to provide a meaningful advantage over human talent scouts.
The ability to create, edit, and mix and match music will also lead to greater personalization preferences on the part of consumers. We could see music streaming companies enable mix and match capabilities, allowing users to select attributes such as artist and genre type, and create new music that is a variation of a track or a combination of multiple tracks. Music streaming companies could partner to obtain computer-generated content, or develop in-house capabilities, such as Spotify’s research team which has been working on many aspects of audio processing, including music generation.
The emergence of computer-generated music will lead to new legal questions, particularly given there isn’t much law today when it comes to AI writing music. If an AI model creates a slightly different version of an artist’s track, does it violate copyright law? Does an AI system own the music it creates, or can it be copyrighted by the developer? A lot of what gets established will likely follow the precedence of existing media practices, but policies will also be shaped by how media companies support various practices of computer-based music generation.
The holy grail of computer-generated music, the ability to fully generate the quality, variety and human aspect of music, would drastically change music as we know it today if achieved. Improvements in computer-generated music to reach this level will, however, require many advances from where we stand today, and even then, there will exist value for music created by human artists, as well.
What we can say with certainty today is that software is starting to redefine music, and the ability to mix and match different tracks from your favorite artists, or create new ones on your own with their voices, is likely only around the corner.