
It was not long ago that the world watched World Chess Champion Garry Kasparov lose a decisive match against a supercomputer. IBM’s Deep Blue embodied the state of the art in the late 1990s, when a machine defeating a world (human) champion at a complex game such as chess was still unheard of.
Fast-forward to today, and not only have supercomputers greatly surpassed Deep Blue in chess, they have managed to achieve superhuman performance in a string of other games, often much more complex than chess, ranging from Go to Dota to classic Atari titles.
Many of these games have been mastered just in the last five years, pointing to a pace of innovation much quicker than the two decades prior. Recently, Google released work on Agent57, which for the first time showcased superior performance over existing benchmarks across all 57 Atari 2600 games.
The class of AI algorithms underlying these feats — deep-reinforcement learning — has demonstrated the ability to learn at very high levels in constrained domains, such as the ones offered by games.
The exploits in gaming have provided valuable insights (for the research community) into what deep-reinforcement learning can and cannot do. Running these algorithms has required gargantuan compute power as well as fine-tuning of the neural networks involved in order to achieve the performance we’ve seen.
Researchers are pursuing new approaches such as multi-environment training and the use of language modeling to help enable learning across multiple domains, but there remains an open question of whether deep-reinforcement learning takes us closer to the mother lode — artificial general intelligence (AGI) — in any extensible way.
While the talk of AGI can get quite philosophical quickly, deep-reinforcement learning has already shown great performance in constrained environments, which has spurred its use in areas like robotics and healthcare, where problems often come with defined spaces and rules where the techniques can be effectively applied.
In robotics, it has shown promising results in using simulation environments to train robots for the real world. It has performed well in training real-world robots to perform tasks such as picking and how to walk. It’s being applied to a number of use cases in healthcare, such as personalized medicine, chronic care management, drug discovery and resource scheduling and allocation. Other areas that are seeing applications have included natural language processing, computer vision, algorithmic optimization and finance.
The research community is still early in fully understanding the potential of deep-reinforcement learning, but if we are to go by how well it has done in playing games in recent years, it’s likely we’ll be seeing even more interesting breakthroughs in other areas shortly.
So what is deep-reinforcement learning?
If you’ve ever navigated a corn maze, your brain at an abstract level has been using reinforcement learning to help you figure out the lay of the land by trial and error, ultimately leading you to find a way out.
Reinforcement learning (that’s without the “deep”) involves an agent exploring an environment many times over, gradually learning which actions it should take in different situations in order to achieve its goals.
Its reliance on exploration and learning by trial and error make it very different from other forms of machine learning, which consist of supervised and unsupervised learning. Supervised learning involves learning from a training set of labeled examples, such as labeling 1,000 pictures of dogs and then having an algorithm identify whether a new photo shows a dog. Meanwhile, unsupervised learning involves learning from the underlying structure of unlabeled data, such as having an algorithm cluster of 1,000 unlabeled photos containing either a dog or a cat divided into two groups and letting it learn to cluster them based on animal type.
In recent years, deep-learning techniques using neural networks have been used in conjunction with reinforcement learning, resulting in a novel approach called “deep-reinforcement learning.” Neural networks can better model high-level abstractions during the learning process, and combining the two techniques together has yielded state-of-the-art results across many problem areas.
Let’s get slightly more technical, though, to understand the nuances here. Reinforcement-learning algorithms are typically modeled as a Markov Decision Process, with an agent in an environment, as modeled in the diagram below.
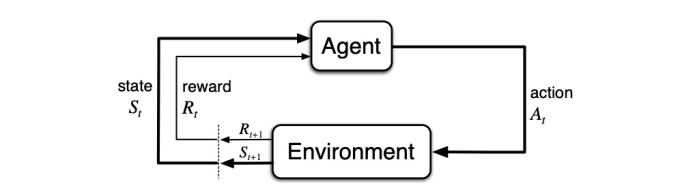
Image Credits: Sutton & Barto (opens in a new window)
At each step in time, the agent is in a certain state in the environment. The agent takes an action in the state, which results in the agent moving to a new state and receiving a reward.
Consider the earlier example of a person trying to escape a corn maze. In this case, the agent would be the person, and the environment would be the corn maze.
A state could constitute a specific part of the corn maze the person is in. An action could be the ability to take a step back, forward, left or right. The set of actions possible in a given state would be variable, since in some parts of the maze, walking in a certain direction may not be possible. The reward could be a numerical value assigned to a step that results in escaping the maze successfully.
A reinforcement-learning algorithm would thus have the system try to escape the maze many times, receiving rewards when it escapes and letting it recall which steps were taken to make that happen. This would help it learn the potential best possible actions to take in different positions in the maze over time.
Now, let’s take a more complex example of a game of chess. Here, the agent would be the chess player, and the environment would be composed of the pieces as well as the rules of the game, such as how the movements of pawns and knights differ.
The state is essentially a snapshot of the chess board at a specific moment in time, including the positions of all the pieces. Each state offers a viable set of moves for the player, constituting the set of actions. A reward would be given when a player wins the game, in order to motivate the player to make moves that eventually lead to victory.
A proper reward system helps the agent prioritize the right goals and learn the best actions across states over time. In chess, it can be tempting to assign a reward to capturing pieces, but this can result in the system focusing on capturing pieces and losing sight of winning the game.
A reinforcement-learning algorithm would thus have the system play lots of chess games (think potentially billions of them), enabling it to learn the best potential moves in a wide array of states that maximize its ability to win the game.
The agent’s policy is another important concept, representing how an agent decides which action to take in a given state. The policy involves selecting an action that helps maximize rewards over the long term. The agent is able to improve its policy over time by correlating which actions in a given state lead it to achieve greater rewards over time.
Reinforcement-learning algorithms face a trade-off between exploitation and exploration, in terms of the action taken at each step during the learning process. Exploration happens when a system chooses an arbitrary action, whereas exploitation occurs when the system chooses the action maximizing its rewards. A well-trained system typically requires both processes to occur with some probability between 0 and 1 which is set initially and can vary through the course of training.
Over time, a well-configured reinforcement-learning algorithm explores the environment during training by going through many states, taking different actions and improving its policy by learning to take actions that help maximize its rewards in the long term.
Deep-reinforcement learning isn’t different from this framework, but instead uses neural networks to model the policy during training. Neural networks are also increasingly being used to model the state in games such as Dota 2, where unlike chess, which has a finite set of positions for a finite set of pieces, the machine has to process the visual input to understand what’s going on at any given point in time.
How OpenAI and Google’s DeepMind are actively beating humans
Games have been a popular test bed for much of the early work on deep-reinforcement learning. Games tend to have constrained environments with explicit definitions of rules, and they also typically have numerical ways to track performance. They also harbor the complexity needed for intelligent systems to be able to achieve higher levels of performance over existing benchmarks.
OpenAI, founded by Elon Musk, Sam Altman and others, showed promising results playing Dota 2, a complex strategy game, over the course of a multi-year project, which culminated with their system beating the Dota 2 world champions last year.
Google DeepMind’s recent results with the Agent57 project were based on state-of-the-art improvements made to a system they’ve been building to play Atari games since 2012, when they first proposed a novel deep-reinforcement learning approach that involved a neural network called DQN. Previously, the team had demonstrated the ability to surpass top level human players in both Go and Chess with the AlphaGo project and its extended version, AlphaZero. Beyond these projects, they’ve also shown promising results in playing Capture the Flag.
In addition, other independent groups have demonstrated top-level performance on games, including work on Poker with project DeepStack, work on StarCraft II and work on Hex.
OpenAI’s work on Dota 2 has been particularly impressive, given the complexity of Dota 2, which has more than 100+ characters and can have 200K+ moves through the course of a game based on a reasonable sampling rate. Relative to games such as Go or Chess, Dota 2 carries a lot more variability and messiness, much like the real world. Furthermore, Dota 2 requires long-term planning, as most moves yield minimal gains in the short-term and map activity is often partially obscured due to factors such as fog and buildings that impede a player’s view.
The system OpenAI built, OpenAI Five, was trained with more than 180 years of games played daily against itself. The system would initially spend a few days simply exploring, after which it would learn concepts such as laning and farming. It would subsequently adopt basic human strategies, and after more time, begin to exhibit high-level strategies such as sacrificing its own lane and moving transitions to the mid-game quicker than human players.
The effort since 2016 resulted in a win against the Dota 2 world champions last year. During the match, the OpenAI team also demonstrated the system’s ability to play cooperatively alongside humans, which piqued much interest in the AI community on the potential for human-computer collaboration.
Google DeepMind’s recently released work on Atari games (which you can watch here) consists of a deep-reinforcement learning system called Agent57, which surpassed existing baselines across all 57 of the Atari 2600 games, a benchmark called the Arcade Learning Environment that was set back in 2012.
The work is particularly significant, given that it scored well on four particular games — Montezuma’s Revenge, Pitfall, Solaris and Skiing — which the AI research community had struggled with until now. These games were particularly difficult, because it has been a challenge getting the exploration-exploitation trade-off right, as well as enabling the system to value long-term rewards effectively.
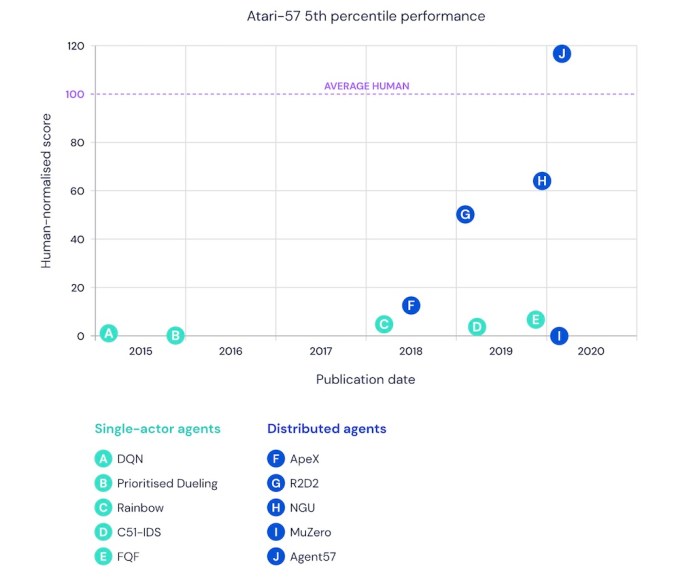
Image Credits: Google DeepMind’s Agent57 (opens in a new window)
The team’s ability to overcome these challenges resulted from continued improvements made to the initial deep-reinforcement learning algorithm called DQN, which they had built back in 2012. One of the main additions involved building in short-term and episodic memory structures into DQN, enabling the agent to better aggregate memory from past events to inform decision making.
Consider the case of finding ice cream in a crowded freezer. If you were looking to find strawberry ice cream and found vanilla ice cream along the way, you may still wish to remember how you found the vanilla ice cream in case you wanted to find it later. The inclusion of this capability helped performance in a game called Pitfall.
Another aspect the team tackled involved optimizing the level of exploration versus exploitation and the time horizon the agent used for long-term learning of rewards. The improvements made in the past year to DQN highlight the importance of optimal model building with deep-reinforcement algorithms for best performance, in addition to the use of heavy compute resources.
Better simulations are helping real-world robots
Gaming has seen huge strides, but the application of deep-reinforcement learning doesn’t end there. Within robotics, researchers have become interested in an approach dubbed “sim-to-real,” which involves using deep-reinforcement learning and other techniques to enable robots to train in simulation and then perform effectively in the real world.
Training robots in the real world has always been difficult because they are mechanical and therefore learn more slowly. Unfortunately, training a robot in simulation has traditionally led to poor performance, as there’s often esoteric noise in the real world for which a simulation environment isn’t fully able to prepare the robot.
That gap is starting to narrow though. Dr. Pieter Abbeel, a CS professor at Berkeley and co-director of the university’s Robot Learning Lab, has in recent years worked on a number of techniques that leverage deep-reinforcement learning in helping robots learn. These include domain randomization, along with others such as imitation learning, one-shot-learning, value-based learning, policy-based learning and model-based learning.
“Domain randomization involves using a wide range of simulation environments during training, which better enable a robot to deal with the real world,” says Abbeel. “Simulation training has traditionally not translated well to the real world, but we’re seeing promise with techniques such as domain randomization and others which help improve the transfer learning ability.”
He and his team demonstrated in 2017 results that showed improved performance with use of domain randomization by effectively making the robot learn from a variety of simulation environments, leading it to view the real world as yet another simulation environment similar to the ones seen during training. More recently, they showed promising results using domain randomization to help robots better track their body positioning, enabling more accurate movements and responses to the environment.
OpenAI has also used deep-reinforcement learning in robotics applications, including leveraging techniques such as domain randomization. OpenAI built a system late last year that involved a robot hand successfully solving a Rubik’s Cube.
The system was trained fully in simulation, using domain randomization to expose the robot to a wide range of conditions that included varying the size of the Rubik’s Cube, the mass of the Rubik’s Cube and the friction of the robot’s fingers.
The OpenAI team automated the exploration of ranges for these variables during simulation, leading to a more automated approach called Automatic Domain Randomization (ADR). This automated approach led to better results than when the variable ranges were set manually. For simple scrambles that included fewer than 15 cube flips, their system was successful 60% of the time, and for the maximal scramble of 26 flips it was successful 20% of the time.
Teaching robots how to walk has been a task that’s garnered much focus as well. A team at Google released work earlier this year that used deep-reinforcement learning to successfully teach a robot how to walk in less than two hours, and similar work has been ongoing in research labs at Berkeley, Stanford, MIT and other research institutions.
In the industrial realm, companies are leveraging deep-reinforcement learning to enable real-world robots to automate tasks in manufacturing and other domains.
Covariant Robotics, a company co-founded by Abbeel that came out of stealth in February, is building algorithms based on deep-reinforcement learning, enabling robots to learn tasks that traditionally programmed robots haven’t been capable of doing. They announced a partnership with automation company ABB recently, which involves the use of a fully autonomous system for e-commerce fulfillment.
Osaro, which announced a $16 million Series B round late last year, is another company in the robotics space leveraging deep-reinforcement learning. Osaro’s Pick product automates sorting, picking and assembling of objects under constraints such as variable container and item placements. Osaro works alongside partners to help source robots they integrate with their software for end customers, enabling the robots to be used across a diverse set of functional roles.
Deep-reinforcement learning is quickly expanding
Beyond the domains of gaming and robotics, deep-reinforcement learning has been seeing growing adoption across a number of different verticals.
Healthcare has been one of those areas. Deep-reinforcement learning is being applied to medical imaging, helping with diagnostic readings by outlining objects of interest in images for radiologists. Chronic care management has traditionally consisted of using a sequence of medical treatment protocols, and these processes are being optimized with deep-reinforcement learning to find optimal protocol sequences.
January.ai is a startup that’s leveraging deep-reinforcement learning to help patients assess their behavioral and clinical data to create personalized plans of action for measurable outcomes. A number of other applications in healthcare have included resource scheduling and allocation, optimal process control and drug discovery.
Deep-reinforcement learning is also being applied to help optimize algorithms themselves.
Google Brain used deep-reinforcement learning to perform neural architecture search, which involved optimizing neural network architectures using a trial-and-error technique. Researchers have explored combinatorial optimization, in which a system learns which algorithms work best for solving common classes of optimization problems.
Natural language processing (NLP) and computer vision have been other areas where deep-reinforcement learning has been commonly used, particularly along information extraction tasks such as summarization, Q&A and object identification, such as identifying company names in a given text. These new approaches have shown improvements over supervised learning in at least some instances.
Beyond these three areas, deep-reinforcement learning is being applied to a number of different areas that have included personalized recommendations, bidding and advertising, optimization of compute resources, chemistry, finance and others.
The strong performance of deep-reinforcement learning in playing games came after several years of iterative work by multiple research groups. Many of the applications in the areas beyond gaming are still in their early days, and it’s likely we’ll get a better understanding of how deep-reinforcement learning can work in these domains over the coming years as more teams work on these problems.
A future of possibilities, but also of limitations
One of the main challenges of deep-reinforcement learning has been the large amounts of compute resources required to train a system effectively. This is primarily due to the trial-and-error fashion in which the algorithm slowly learns over time.
In the case of OpenAI’s work on Dota 2, the OpenAI Five system utilized 256 GPUs and 128,000 CPUs, allowing itself to play more than 180 years of games in a single day. Other projects have similarly required large amounts of hardware for compute.
Better model construction and higher-quality training data have both been used extensively to reduce the compute requirements to the extent possible. In Google’s work with AlphaZero, the system was able to play chess at superhuman level within four hours of training, using 5,000 first-generation TPUs and 64 second-generation TPUs.
Part of the reason behind this time efficiency for training was the way the model was constructed, enabling AlphaZero to perform at a high level by searching only 80,000 positions per second as opposed to 70 million positions per second as is the case for Stockfish, a popular chess engine that uses more traditional algorithms.
The system also learned via self-play only, with no access to opening books, endgame tables or human games, which helped the system learn at a high level by avoiding influences from human moves regarding how to play.
Teams from Google Brain and Google DeepMind released work on data-efficient training earlier this year aimed at making the exploration part of deep-reinforcement learning systems more efficient. The team at Google Brain proposed Adaptive Behavior Policy Sharing (ABPS), an optimization strategy that allows selective sharing of information from a pool of agents trained on an ensemble of parameters. The team at Google DeepMind proposed strategies such as NGU for more efficient exploration strategies using memory, which were incorporated into work on Agent57.
Another method being explored to make deep-reinforcement learning algorithms more efficient is the use of language modeling to enable faster learning of high-level abstractions.
“Reinforcement-learning algorithms require a great degree of exploration, often incurring large compute times. Language modeling has potential to enable faster learning by allowing a system to learn high-level abstractions more efficiently in many scenarios,” says Dr. Karthik Narasimhan, a CS professor at Princeton.
Consider the example of a system learning to play tennis, from the standpoint of how it figures out where to stand after serving. In a traditional training setup, the system would try to position itself across the entire court, requiring a lot of exploration for it to learn concepts of baseline play and volleying.
Language modeling could be used in such a case to help it learn to position itself in certain parts of the court during returns and focus on exploring those positions more thoroughly than others. Words can thereby let the system learn something that might otherwise take a lot of trial and error, reducing the complexity of the learning process and therefore the compute requirements.
One challenge for deep-reinforcement learning is that most systems continue to work well only within a singular environment. As the AI community looks ahead, there’s an increased focus on experimenting with multi-environment training, where a system is trained to perform multiple different tasks at once.
Multi-environment training could involve a system playing multiple games with the same model architecture, or a robot learning to perform multiple motions with separate factors involved at once. Advances on this front would require newer models that can learn more efficiently across multiple environments, and given the compute resources necessary might also require other advances such as language modeling.
Regardless of how such efforts pan out in the future, it is exciting to see the potential deep-reinforcement learning has shown in solving problems with constrained environments. Many real-life situations, such as robots in manufacturing plants picking items or the processing of structured medical images, do often contain reasonably constrained environments where deep-reinforcement learning can work well. It’s likely the efforts on gaming will continue in the early 2020s, but it’s also likely we’ll be seeing many new applications crop up that we could not have imagined before.