
AI is frequently cited as a miracle worker in medicine, especially in screening processes, where machine learning models boast expert-level skills in detecting problems. But like so many technologies, it’s one thing to succeed in the lab, quite another to do so in real life — as Google researchers learned in a humbling test at clinics in rural Thailand.
Google Health created a deep learning system that looks at images of the eye and looks for evidence of diabetic retinopathy, a leading cause of vision loss around the world. But despite high theoretical accuracy, the tool proved impractical in real-world testing, frustrating both patients and nurses with inconsistent results and a general lack of harmony with on-the-ground practices.
It must be said at the outset that although the lessons learned here were hard, it’s a necessary and responsible step to perform this kind of testing, and it’s commendable that Google published these less than flattering results publicly. It’s also clear from their documentation that the team has already taken the results to heart (although the blog post presents a rather sunny interpretation of events).
The research paper documents the deployment of a tool meant to augment the existing process by which patients at several clinics in Thailand are screened for diabetic retinopathy, or DR. Essentially nurses take diabetic patients one at a time, take images of their eyes (a “fundus photo”), and send them in batches to ophthalmologists, who evaluate them and return results…. usually at least 4-5 weeks later due to high demand.
The Google system was intended to provide ophthalmologist-like expertise in seconds. In internal tests it identified degrees of DR with 90% accuracy; the nurses could then make a preliminary recommendation for referral or further testing in a minute instead of a month (automatic decisions were ground truth checked by an ophthalmologist within a week). Sounds great — in theory.
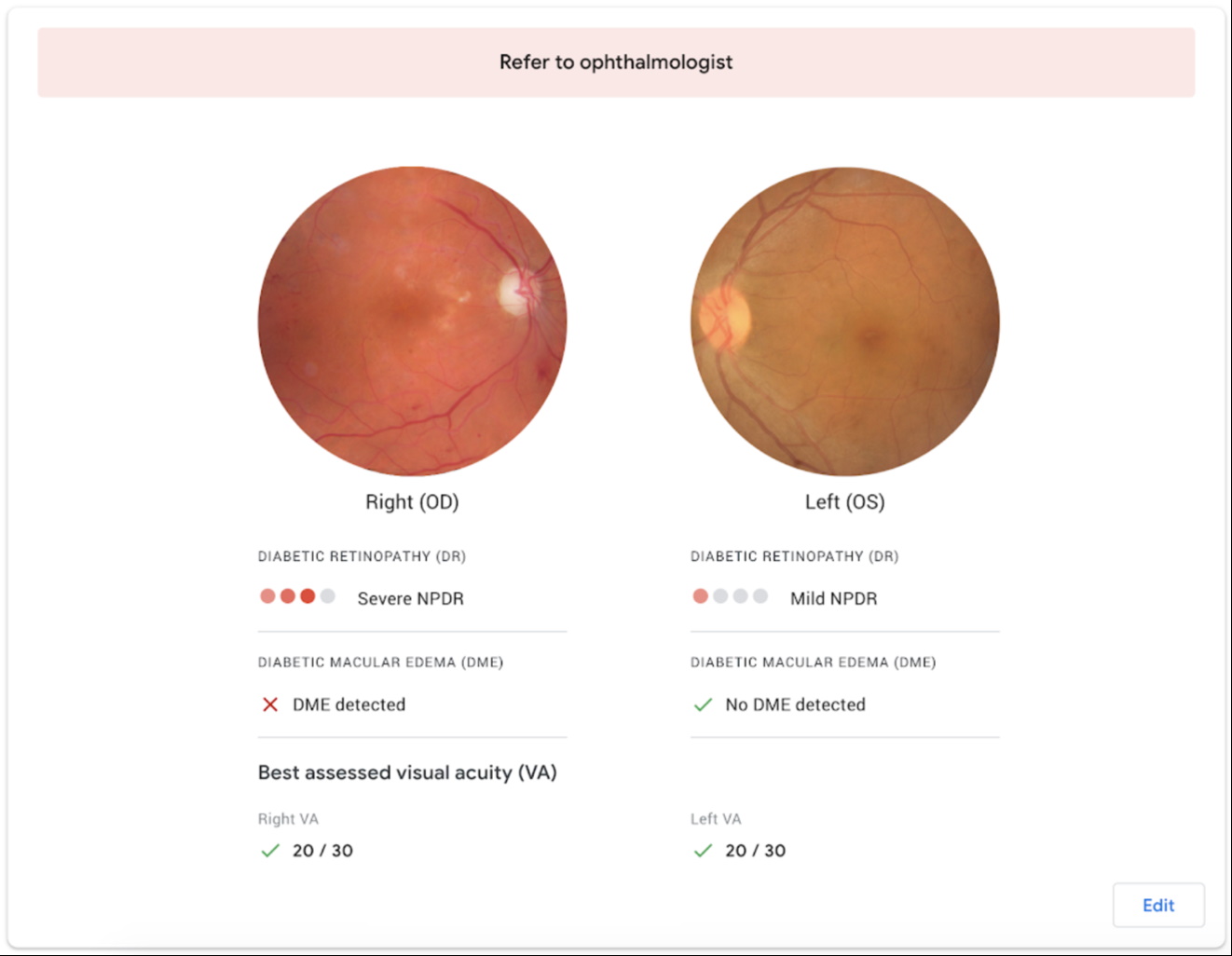
Ideally the system would quickly return a result like this, which could be shared with the patient.
But that theory fell apart as soon as the study authors hit the ground. As the study describes it:
We observed a high degree of variation in the eye-screening process across the 11 clinics in our study. The processes of capturing and grading images were consistent across clinics, but nurses had a large degree of autonomy on how they organized the screening workflow, and different resources were available at each clinic.
The setting and locations where eye screenings took place were also highly varied across clinics. Only two clinics had a dedicated screening room that could be darkened to ensure patients’ pupils were large enough to take a high-quality fundus photo.
The variety of conditions and processes resulted in images being sent to the server not being up to the algorithm’s high standards:
The deep learning system has stringent guidelines regarding the images it will assess…If an image has a bit of blur or a dark area, for instance, the system will reject it, even if it could make a strong prediction. The system’s high standards for image quality is at odds with the consistency and quality of images that the nurses were routinely capturing under the constraints of the clinic, and this mismatch caused frustration and added work.
Images with obvious DR but poor quality would be refused by the system, complicating and extending the process. And that’s when they could get them uploaded to the system in the first place:
On a strong internet connection, these results appear within a few seconds. However, the clinics in our study often experienced slower and less reliable connections. This causes some images to take 60-90 seconds to upload, slowing down the screening queue and limiting the number of patients that can be screened in a day. In one clinic, the internet went out for a period of two hours during eye screening, reducing the number of patients screened from 200 to only 100.
“First, do no harm” is arguably in play here: Fewer people in this case received treatment because of an attempt to leverage this technology. Nurses tried various workarounds but the inconsistency and other factors led some to advise patients against taking part in the study at all.
Even the best case scenario had unforeseen consequences. Patients were not prepared for an instant evaluation and setting up a follow-up appointment immediately after sending the image:
As a result of the prospective study protocol design, and potentially needing to make on-the-spot plans to visit the referral hospital, we observed nurses at clinics 4 and 5 dissuading patients from participating in the prospective study, for fear that it would cause unnecessary hardship.
As one of those nurses put it:
“[Patients] are not concerned with accuracy, but how the experience will be—will it waste my time if I have to go to the hospital? I assure them they don’t have to go to the hospital. They ask, ‘does it take more time?’, ‘Do I go somewhere else?’ Some people aren’t ready to go so won’t join the research. 40-50% don’t join because they think they have to go to the hospital.”
It’s not all bad news, of course. The problem is not that AI has nothing to offer a crowded Thai clinic, but that the solution needs to be tailored to the problem and the place. The instant, easily understood automatic evaluation was enjoyed by patients and nurses alike when it worked well, sometimes helping make the case that this was a serious problem that had to be addressed soon. And of course the primary benefit of reducing dependence on a severely limited resource (local ophthalmologists) is potentially transformative.
But the study authors seemed clear-eyed in their evaluation of this premature and partial application of their AI system. As they put it:
When introducing new technologies, planners, policy makers, and technology designers did not account for the dynamic and emergent nature of issues arising in complex healthcare programs. The authors argue that attending to people—their motivations, values, professional identities, and the current norms and routines that shape their work—is vital when planning deployments.
The paper is well worth reading both as a primer in how AI tools are meant to work in clinical environments and what obstacles are faced — both by the technology and those meant to adopt it.