
Consumer expectations are higher than ever as a new generation of shoppers look to shop for experiences rather than commodities. They expect instant and highly-tailored (pun intended?) customer service and recommendations across any retail channel.
To be forward-looking, brands and retailers are turning to startups in image recognition and machine learning to know, at a very deep level, what each consumer’s current context and personal preferences are and how they evolve. But while brands and retailers are sitting on enormous amounts of data, only a handful are actually leveraging it to its full potential.
To provide hyper-personalization in real time, a brand needs a deep understanding of its products and customer data. Imagine a case where a shopper is browsing the website for an edgy dress and the brand can recognize the shopper’s context and preference in other features like style, fit, occasion, color etc., then use this information implicitly while fetching similar dresses for the user.
Another situation is where the shopper searches for clothes inspired by their favorite fashion bloggers or Instagram influencers using images in place of text search. This would shorten product discovery time and help the brand build a hyper-personalized experience which the customer then rewards with loyalty.
With the sheer amount of products being sold online, shoppers primarily discover products through category or search-based navigation. However, inconsistencies in product metadata created by vendors or merchandisers lead to poor recall of products and broken search experiences. This is where image recognition and machine learning can deeply analyze enormous data sets and a vast assortment of visual features that exist in a product to automatically extract labels from the product images and improve the accuracy of search results.
Why is image recognition better than ever before?
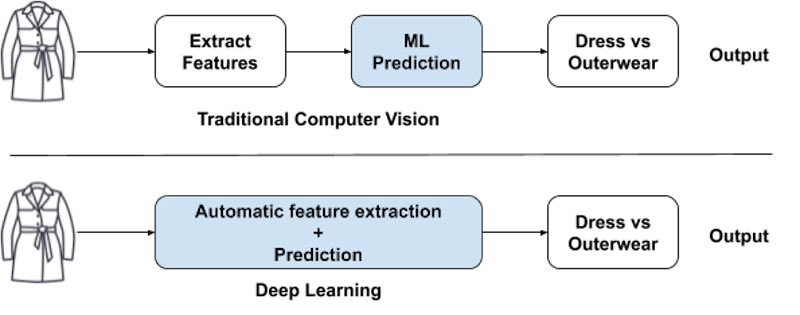
While computer vision has been around for decades, it has recently become more powerful, thanks to the rise of deep neural networks. Traditional vision techniques laid the foundation for learning edges, corners, colors and objects from input images but it required human engineering of the features to be looked at in the images. Also, the traditional algorithms found it difficult to cope up with the changes in illumination, viewpoint, scale, image quality, etc.
Deep learning, on the other hand, takes in massive training data and more computation power and delivers the horsepower to extract features from unstructured data sets and learn without human intervention. Inspired by the biological structure of the human brain, deep learning uses neural networks to analyze patterns and find correlations in unstructured data such as images, audio, video and text. DNNs are at the heart of today’s AI resurgence as they allow more complex problems to be tackled and solved with higher accuracy and less cumbersome fine-tuning.
How much training data do you need?
Training a deep learning model from scratch does require a large amount of data, but thanks to a technique called transfer learning, deep learning models can be trained with little data as well. Transfer learning is a popular approach in which a model previously trained for one task is reused for another closely-related task. For example, knowledge gained while learning to recognize tops can be reused to some degree to recognize dresses. For vision tasks, deep learning models pre-trained for a large image classification task such as the ImageNet 1000-class is commonly used. Oxford VGG Model, Google Inception Model, Microsoft ResNet Model are some of the pre-trained models that can be downloaded and applied to solve for image recognition, more examples can be found on Tensorflow Hub, Caffe Model Zoo.
The way to fine-tune a pretrained model depends on how big the new dataset is and how close it is to the original dataset. The earlier layers of a ConvNet extracts more generic features like edges and colors, but later layers of the ConvNet become more specific to the classes defined in the original dataset. If the new dataset is very close to the original dataset or is very small, it would be better to reuse as many layers as possible from the original network and only retrain the final layers. A pretrained model using imagenet has not only been trained for fashion items like cardigans and overskirt but also for triceratops, broccoli, oxygen mask etc. So to repurpose this model to predict features of a top like fit, style, neck style will require retraining last few layers of the model with dataset specifically annotated for the required features. With larger amount of data, the whole network can be retrained with weights initialized from the pre-trained network.
Which ML framework works best?
Machine learning frameworks like Tensorflow, PyTorch, Keras etc. enable businesses to build machine learning models easily. All of them are open source and come with pretrained models. Tensorflow developed by Google, is the most popular and well maintained library with support for multiple languages like Python, C++.
However, the TensorFlow interface can be challenging for new users, as it is a more low-level library. Keras, on the other hand, is the most beginner-friendly and provides a high-level API that allows for focusing on experimentation and observing quick results. Pytorch is relatively new but is seeing a high level of adoption due to its light weight and support for dynamic computation graphs and efficient memory usage. Deeplearning4j is a deep learning framework written in Java. If the team is looking to just get started, then a Python-based deep learning framework like Keras or Pytorch could be chosen. For more seasoned teams, consider the best deep learning framework optimized for performance.
Image recognition as a service
There are a lot of off the shelf solutions on the market developed by companies like Google, Microsoft, IBM, Amazon, and others which provide deep learning based image recognition service through REST APIs without having to build and train their own convolutional neural networks. These services are a great place for rapid experimentation. They provide the ability to use their pretrained models to categorize image content according to the taxonomy defined by them. The quality and relevance of these tags vary from one platform to another depending on the image quality and the kind of task (some models might be good at accurately categorizing the dominant content while some might be capturing everything including the items in the background).
Since these are mostly generic models that apply across categories, trying to extract deep or domain-specific features from these models may not be feasible. At Lily AI, our universal taxonomy just for fashion has thousands of attributes, trained based on nearly 1 billion data points, which enables the deep level of attributes we can extract from product data. Other types of API services provide the capability to create a custom vision model and feed it with labeled training data. However this approach does not provide the end consumer the ability to tinker (passively or actively) with the models to fine tune its parameters for improving accuracy of the specific use case. All you could do with those models is pump in more data assuming that humans involved in the data annotation process have been trained for consistency and in consensus with each other.
Hyper-personalization is no longer a trend but a mandate in retail. The ability to understand customer behavior was the first-step to understanding true buyer motivations. Product features extracted through image recognition have the potential to be one of the most fundamental datasets underlying a complete understanding of why shoppers buy and to be able to convert their preferences into unique experiences. Automating the extraction of this data using AI will enable brands and retailers to quickly and continuously build the customer insight that drives customer growth and loyalty.