Many companies and municipalities are saddled with hundreds or thousands of hours of video and limited ways to turn it into usable data. Voxel51 offers a machine learning-based option that chews through video and labels it, not just with simple image recognition but with an understanding of motions and objects over time.
Annotating video is an important task for a lot of industries, the most well-known of which is certainly autonomous driving. But it’s also important in robotics, the service and retail industries, for police encounters (now that body cams are becoming commonplace) and so on.
It’s done in a variety of ways, from humans literally drawing boxes around objects every frame and writing what’s in it to more advanced approaches that automate much of the process, even running in real time. But the general rule with these is that they’re done frame by frame.
A single frame is great if you want to tell how many cars are in an image, or whether there’s a stop sign, or what a license plate reads. But what if you need to tell whether someone is walking or stepping out of the way? What about whether someone is waving or throwing a rock? Are people in a crowd going to the right or left, generally? This kind of thing is difficult to infer from a single frame, but looking at just two or three in succession makes it clear.
That fact is what startup Voxel51 is leveraging to take on the established competition in this space. Video-native algorithms can do some things that single-frame ones can’t, and where they do overlap, the former often does it better.
Voxel51 emerged from computer vision work done by its co-founders, CEO Jason Corso and CTO Brian Moore, at the University of Michigan. The latter took the former’s computer vision class and eventually the two found they shared a desire to take ideas out of the lab.
“I started the company because I had this vast swath of research,” Corso said, “and the vast majority of services that were available were focused on image-based understanding rather than video-based understanding. And in almost all instances we’ve seen, when we use a video-based model we see accuracy improvements.”
While any old off-the-shelf algorithm can recognize a car or person in an image, it takes much more savvy to make something that can, for example, identify merging behaviors at an intersection, or tell whether someone has slipped between cars to jaywalk. In each of those situations the context is important and multiple frames of video are needed to characterize the action.
“When we process data we look at the spacio-temporal volume as a whole,” said Corso. “Five, 10, 30 frames… our models figure out how far behind and forward it should look to find a robust inference.”
In other, more normal words, the AI model isn’t just looking at an image, but at relationships between many images over time. If it’s not quite sure whether a person in a given frame is crouching or landing from a jump, it knows that it can scrub a little forward or backward to find the information that will make that clear.
And even for more ordinary inference tasks like counting the cars in the street, that data can be double-checked or updated by looking back or skipping ahead. If you can only see five cars because one’s big and blocks a sixth, that doesn’t change the fact that there are six cars. Even if every frame doesn’t show every car, it still matters for, say, a traffic monitoring system.
The natural objection to this is that processing 10 frames to find out what a person is doing is more expensive, computationally speaking, than processing a single frame. That’s certainly true if you are treating it like a series of still images, but that’s not how Voxel51 does it.

“We get away with it by processing fewer pixels per frame,” Corso explained. “The total amount of pixels we process might be the same or less as a single frame, depending on what we want it to do.”
For example, on video that needs to be closely examined but speed isn’t a concern (like a backlog of traffic cam data), it can expend all the time it needs on each frame. But for a case where the turnaround needs to be quicker, it can do a fast, real-time pass to identify major objects and motions, then go back through and focus on the parts that are the most important — not the unmoving sky or parked cars, but people and other known objects.
The platform is highly parameterized and naturally doesn’t share the limitations of human-driven annotation (though the latter is still the main option for highly novel applications where you’d have to build a model from scratch).
“You don’t have to worry about, is it annotator A or annotator B, and our platform is a compute platform, so it scales on demand,” said Corso.
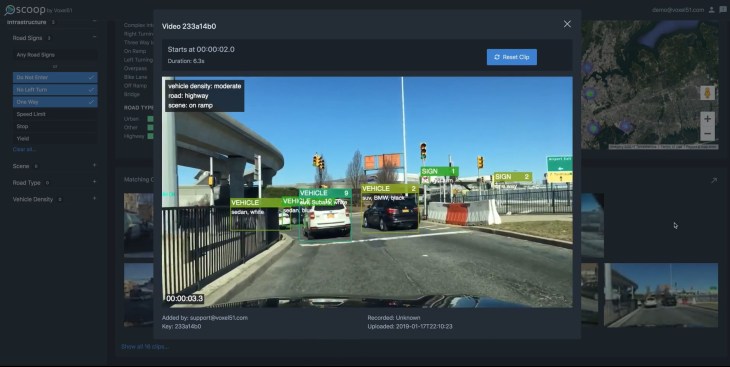
They’ve packed everything into a drag-and-drop interface they call Scoop. You drop in your data — videos, GPS, things like that — and let the system power through it. Then you have a browsable map that lets you enumerate or track any number of things: types of signs, blue BMWs, red Toyotas, right turn only lanes, people walking on the sidewalk, people bunching up at a crosswalk, etc. And you can combine categories, in case you’re looking for scenes where that blue BMW was in a right turn only lane.

Each sighting is attached to the source video, with bounding boxes laid over it indicating the locations of what you’re looking for. You can then export the related videos, with or without annotations. There’s a demo site that shows how it all works.
It’s a little like Nexar’s recently announced Live Maps, though obviously also quite different. That two companies can pursue AI-powered processing of massive amounts of street-level video data and still be distinct business propositions indicates how large the potential market for this type of service is.
Despite its street-feature smarts, Voxel51 isn’t going after self-driving cars to start. Companies in that space, like Waymo and Toyota, are pursuing fairly narrow, vertically oriented systems that are highly focused on identifying objects and behaviors specific to autonomous navigation. The priorities and needs are different from, say, a security firm or police force that monitors hundreds of cameras at once — and that’s where the company is headed right now. That’s consistent with the company’s pre-seed funding, which came from a NIST grant in the public safety sector.

Built with no human intervention from 250 hours of video, a sign/signal map like this would be helpful to many a municipality
“The first phase of go to market is focusing on smart cities and public safety,” Corso said. “We’re working with police departments that are focused on citizen safety. So the officers want to know, is there a fire breaking out, or is a crowd gathering where it shouldn’t be gathering?”
“Right now it’s an experimental pilot — our system runs alongside Baltimore’s CitiWatch,” he continued, referring to a crime-monitoring surveillance system in the city. “They have 800 cameras, and five or six retired cops that sit in a basement watching those — so we help them watch the right feed at the right time. Feedback has been exciting: When [CitiWatch overseer Major Hood] saw the output of our model, not just the person but the behavior, arguing or fighting, his eyes lit up.”
Now, let’s be honest — it sounds a bit dystopian, doesn’t it? But Corso was careful to note that they are not in the business of tracking individuals.
“We’re primarily privacy-preserving video analytics; we have no ability or interest in running face identification. We don’t focus on any kind of identity,” he said.
It’s good that the priority isn’t on identity, but it’s still a bit of a scary capability to be making available. And yet, as anyone can see, the capability is there — it’s just a matter of making it useful and helpful rather than simply creepy. While one can imagine unethical uses like cracking down on protestors, it’s also easy to imagine how useful this could be in an Amber or Silver alert situation. Bad guy in a beige Lexus? Boom, last seen here.
At any rate, the platform is impressive and the computer vision work that went into it even more so. It’s no surprise that the company has raised a bit of cash to move forward. The $2 million seed round was led by eLab Ventures, a Palo Alto and Ann Arbor-based VC firm, and the company earlier attracted the $1.25 million grant from NIST mentioned earlier.
The money will be used for the expected purposes, establishing the product, building out support and the non-technical side of the company and so on. The flexible pricing and near-instant (in video processing terms) results seem like something that will drive adoption fairly quick, given the huge volumes of untapped video out there. Expect to see more companies like Corso and Moore’s as the value of that video becomes clear.