Losing to the computer in StarCraft has been a tradition of mine since the first game came out in 1998. Of course, the built-in “AI” is trivial for serious players to beat, and for years researchers have attempted to replicate human strategy and skill in the latest version of the game. They’ve just made a huge leap with AlphaStar, which recently beat two leading pros 5-0.
The new system was created by DeepMind, and in many ways it’s very unlike what you might call a “traditional” StarCraft AI. The computer opponents you can select in the game are really pretty dumb — they have basic built-in strategies, and know in general how to attack and defend and how to progress down the tech tree. But they lack everything that makes a human player strong: adaptability, improvisation and imagination.
AlphaStar is different. It learned from watching humans play at first, but soon honed its skills by playing against facets of itself.
The first iterations watched replays of games to learn the basics of “micro” (i.e. controlling units effectively) and “macro” (i.e. game economy and long-term goals) strategy. With this knowledge it was able to beat the in-game computer opponents on their hardest setting 95 percent of the time. But as any pro will tell you, that’s child’s play. So the real work started here.

Hundreds of agents were spawned and pitted against each other.
Because StarCraft is such a complex game, it would be silly to think that there’s a single optimal strategy that works in all situations. So the machine learning agent was essentially split into hundreds of versions of itself, each given a slightly different task or strategy. One might attempt to achieve air superiority at all costs; another to focus on teching up; another to try various “cheese” attempts like worker rushes and the like. Some were even given strong agents as targets, caring about nothing else but beating an already successful strategy.
This family of agents fought and fought for hundreds of years of in-game time (undertaken in parallel, of course). Over time the various agents learned (and of course reported back) various stratagems, from simple things such as how to scatter units under an area-of-effect attack to complex multi-pronged offenses. Putting them all together produced the highly robust AlphaStar agent, with some 200 years of gameplay under its belt.
Most StarCraft II pros are well younger than 200, so that’s a bit of an unfair advantage. There’s also the fact that AlphaStar, in its original incarnation anyway, has two other major benefits.
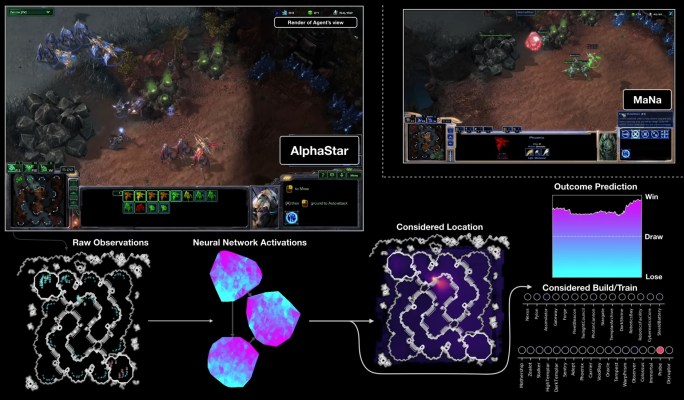
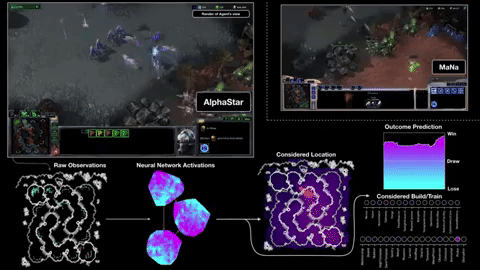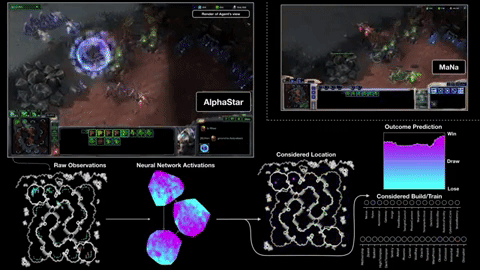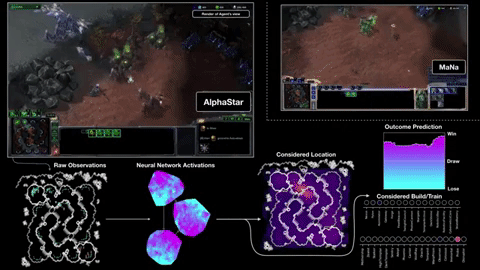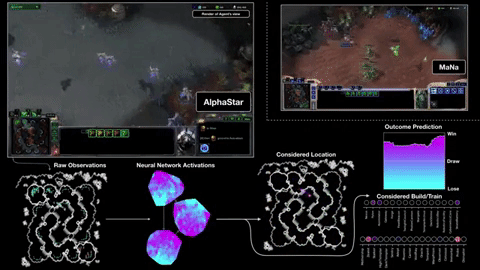 First, it gets its information directly from the game engine, rather than having to observe the game screen — so it knows instantly that a unit is down to 20 HP without having to click on it. Second, it can (though it doesn’t always) perform far more “actions per minute” than a human, because it isn’t limited by fleshy hands and banks of buttons. APM is just one measure among many that determines the outcome of a match, but it can’t hurt to be able to command a guy 20 times in a second rather than two or three.
First, it gets its information directly from the game engine, rather than having to observe the game screen — so it knows instantly that a unit is down to 20 HP without having to click on it. Second, it can (though it doesn’t always) perform far more “actions per minute” than a human, because it isn’t limited by fleshy hands and banks of buttons. APM is just one measure among many that determines the outcome of a match, but it can’t hurt to be able to command a guy 20 times in a second rather than two or three.
It’s worth noting here that AIs for micro control have existed for years, having demonstrated their prowess in the original StarCraft. It’s incredibly useful to be able to perfectly cycle out units in a firefight so none takes lethal damage, or to perfectly time movements so no attacker is idle, but the truth is good strategy beats good tactics pretty much every time. A good player can counter the perfect micro of an AI and take that valuable tool out of play.
AlphaStar was matched up against two pro players, MaNa and TLO of the highly competitive Team Liquid. It beat them both handily, and the pros seemed excited rather than depressed by the machine learning system’s skill. Here’s game 2 against MaNa:
In comments after the game series, MaNa said:
I was impressed to see AlphaStar pull off advanced moves and different strategies across almost every game, using a very human style of gameplay I wouldn’t have expected. I’ve realised how much my gameplay relies on forcing mistakes and being able to exploit human reactions, so this has put the game in a whole new light for me. We’re all excited to see what comes next.
And TLO, who actually is a Zerg main but gamely played Protoss for the experiment:
I was surprised by how strong the agent was. AlphaStar takes well-known strategies and turns them on their head. The agent demonstrated strategies I hadn’t thought of before, which means there may still be new ways of playing the game that we haven’t fully explored yet.
You can get the replays of the matches here.
AlphaStar is inarguably a strong player, but there are some important caveats here. First, when they handicapped the agent by making it play like a human, in that it had to move the camera around, could only click on visible units, had a human-like delay on perception and so on, it was far less strong and in fact was beaten by MaNa. But that version, which perhaps may become the benchmark rather than its untethered cousin, is still under development, so for that and other reasons it was never going to be as strong.
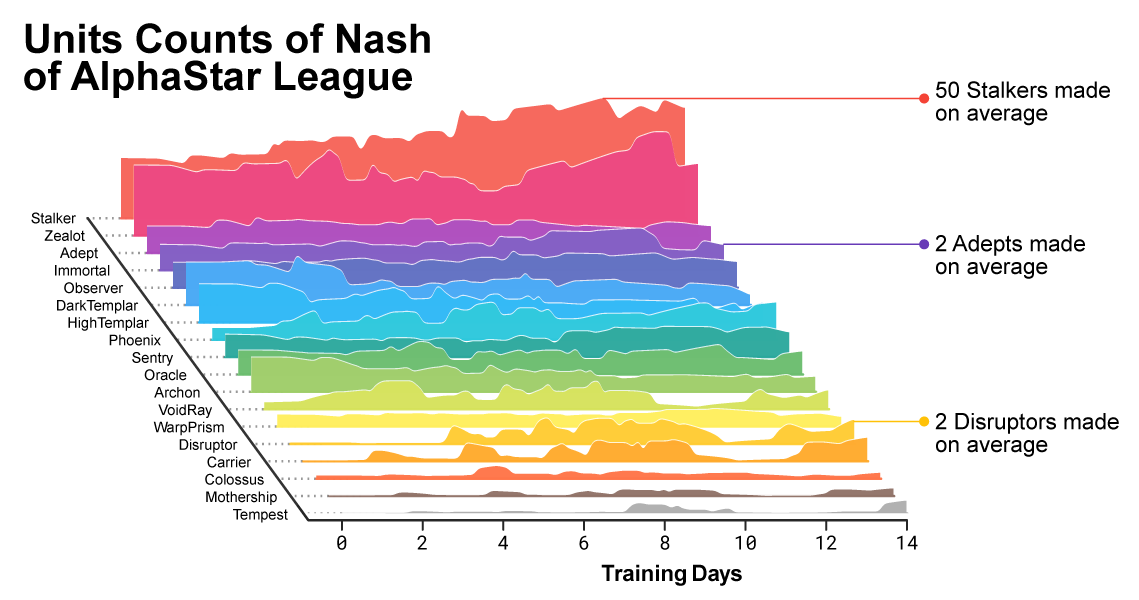
AlphaStar only plays Protoss, and the most successful versions of itself used very micro-heavy units.
Most importantly, though, AlphaStar is still an extreme specialist. It only plays Protoss versus Protoss — probably has no idea what a Zerg looks like — with a single opponent, on a single map. As anyone who has played the game can tell you, the map and the races produce all kinds of variations, which massively complicate gameplay and strategy. In essence, AlphaStar is playing only a tiny fraction of the game — though admittedly many players also specialize like this.
That said, the groundwork of designing a self-training agent is the hard part — the actual training is a matter of time and computing power. If it’s 1v1v1 on Bloodbath maybe it’s stalker/zealot time, while if it’s 2v2 on a big map with lots of elevation, out come the air units. (Is it obvious I’m not up on my SC2 strats?)
The project continues and AlphaStar will grow stronger, naturally, but the team at DeepMind thinks that some of the basics of the system, for instance how it efficiently visualizes the rest of the game as a result of every move it makes, could be applied in many other areas where AIs must repeatedly make decisions that affect a complex and long-term series of outcomes.