
Google and a group of game cetologists have undertaken an AI-based investigation of years of undersea recordings, hoping to create a machine learning model that can spot humpback whale calls. It’s part of the company’s new “AI for social good” program that’s rather obviously positioned to counter the narrative that AI is mostly used for facial recognition and ad targeting.
Whales travel quite a bit as they search for better feeding grounds, warmer waters and social gatherings. But naturally these movements can be rather difficult to track. Fortunately, whales call to each other and sing in individually identifiable ways, and these songs can travel great distances underwater.
So with a worldwide network of listening devices planted on the ocean floor, you can track whale movements — if you want to listen to years of background noise and pick out the calls manually, that is. And that’s how we’ve done it for quite a while, though computers have helped lighten the load. Google’s team, in partnership with NOAA, decided this was a good match for the talents of machine learning systems.
These AI (we employ the term loosely here) models are great at skimming through tons of noisy data for particular patterns, which is why they’re applied to voluminous data like that from radio telescopes and CCTV cameras.
In this case the data was years of recordings from a dozen hydrophones stationed all over the Pacific. This data set has already largely been investigated, but Google’s researchers wanted to see if an AI agent could do the painstaking and time-consuming work of doing a first pass on it and marking periods of interesting sound with a species name — in this case humpbacks, but it could just as easily be a different whale or something else altogether.
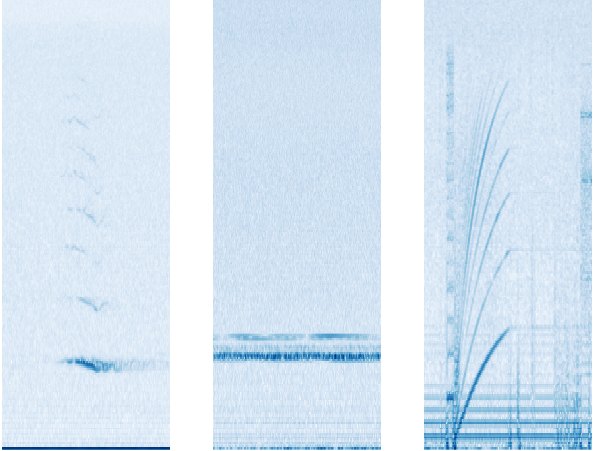
Spectrograms of whale song, left, an unknown “narrow-band” noise, center, and the recorder’s own hard disk drive, right.
Interestingly, but not surprisingly in retrospect, the audio wasn’t analyzed as such — instead, the audio was turned into images it could look for patterns in. These spectrograms are a record of the strength of sound in a range of frequencies over time, and can be used for all kinds of interesting things. It so happens that they’re also well studied by machine learning and computer vision researchers, who have developed various means of analyzing them efficiently.
The machine learning model was provided with examples of humpback whale calls and learned how to identify them with reasonable accuracy in a set of sample data. Various experiments were conducted to suss out what settings were optimal — for instance, what length of clip was easy to process and not overlong, or what frequencies could be safely ignored.
The final effort divided the years of data into 75-second clips, and the model was able to determine, with 90 percent accuracy, whether a clip contained a “humpback unit,” or relevant whale sound. That’s not a small amount of error, of course, but if you trust the machine a bit you stand to save quite a bit of time — or your lab assistant’s time, anyway.
A second effort relied on what’s called unsupervised learning, where the system sort of set its own rules about what constituted similarity between whale sounds and non-whale sounds, creating a plot that researchers could sort through and find relevant groups.
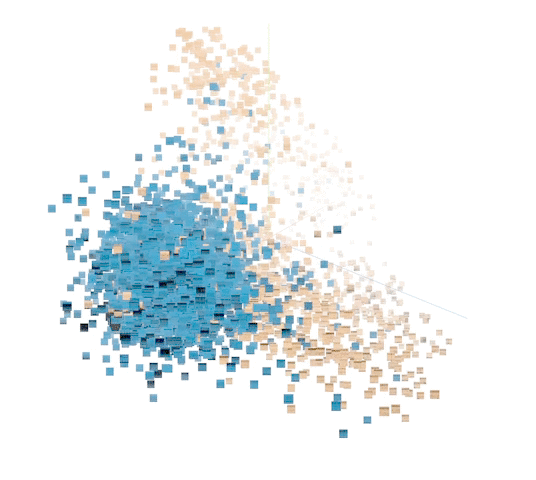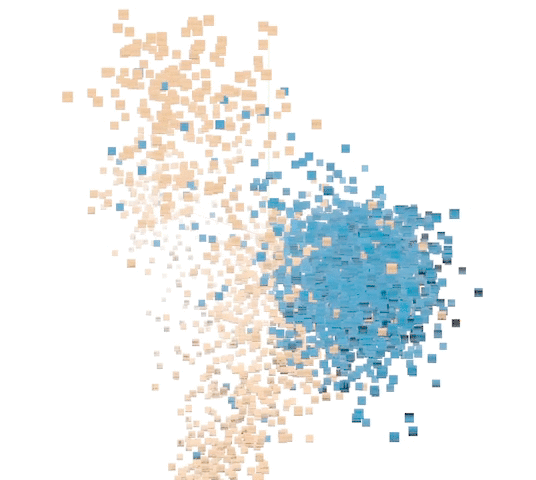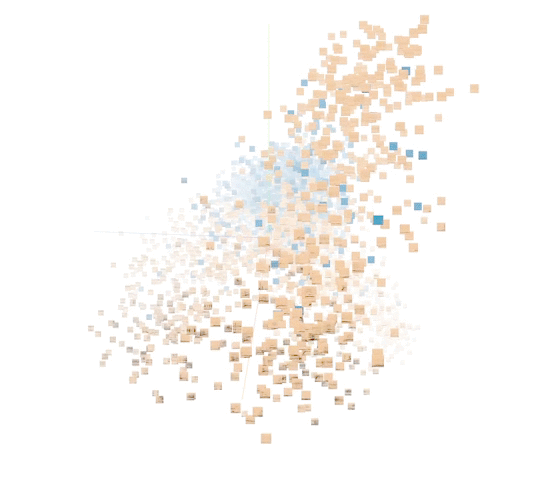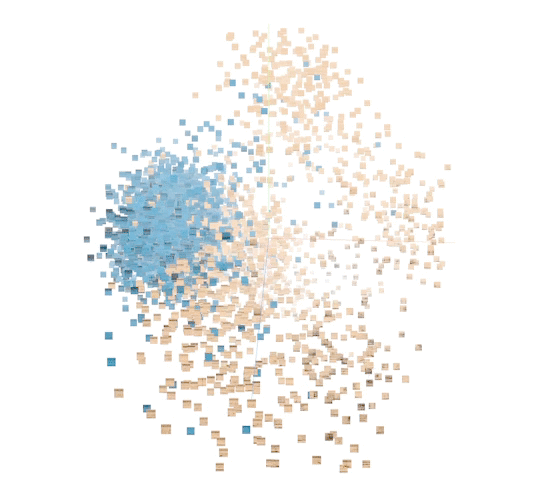
Visualization of how the unsupervised model classified various sounds. The blue ones represent humpback calls.
It makes for more interesting visualizations but it is rather harder to explain, and at any rate doesn’t seem to have resulted in as useful a set of classifications as the more traditional method.
As with similar applications of machine learning in various scholarly fields, this isn’t going to replace careful observation and documentation but rather augment them. Taking some of the grunt work out of science lets researchers focus on their specialties rather than get bogged down in repetitive stats and hours-long data analysis sessions.