With augmented reality coming in hot and depth tracking cameras due to arrive on flagship phones, the time is right to improve how computers track the motions of people they see — even if that means virtually stripping them of their clothes. A new computer vision system that does just that may sound a little creepy, but it definitely has its uses.
The basic problem is that if you’re going to capture a human being in motion, say for a movie or for an augmented reality game, there’s a frustrating vagueness to them caused by clothes. Why do you think motion capture actors have to wear those skintight suits? Because their JNCO jeans make it hard for the system to tell exactly where their legs are. Leave them in the trailer.
Same for anyone wearing a dress, a backpack, a jacket — pretty much anything other than the bare minimum will interfere with the computer getting a good idea of how your body is positioned.
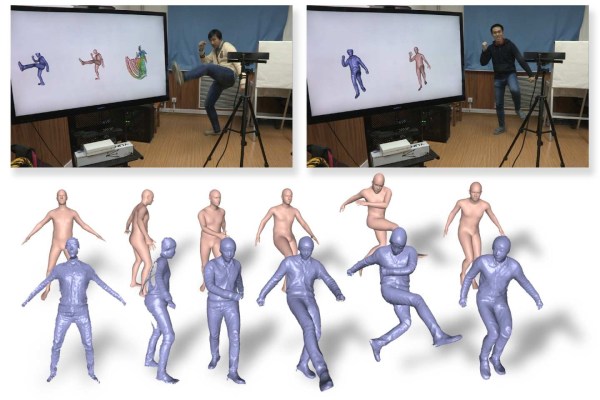
The multi-institutional project (PDF), due to be presented at CVPR in Salt Lake City, combines depth data with smart assumptions about how a body is shaped and what it can do. The result is a sort of X-ray vision, revealing the shape and position of a person’s body underneath their clothes, that works in real time even during quick movements like dancing.
The paper builds on two previous methods, DynamicFusion and BodyFusion. The first uses single-camera depth data to estimate a body’s pose, but doesn’t work well with quick movements or occlusion; the second uses a skeleton to estimate pose but similarly loses track during fast motion. The researchers combined the two approaches into “DoubleFusion,” essentially creating a plausible skeleton from the depth data and then sort of shrink-wrapping it with skin at an appropriate distance from the core.

As you can see above, depth data from the camera is combined with some basic reference imagery of the person to produce both a skeleton and track the joints and terminations of the body. On the right there, you see the results of just DynamicFusion (b), just BodyFusion (c) and the combined method (d).
The results are much better than either method alone, seemingly producing excellent body models from a variety of poses and outfits:
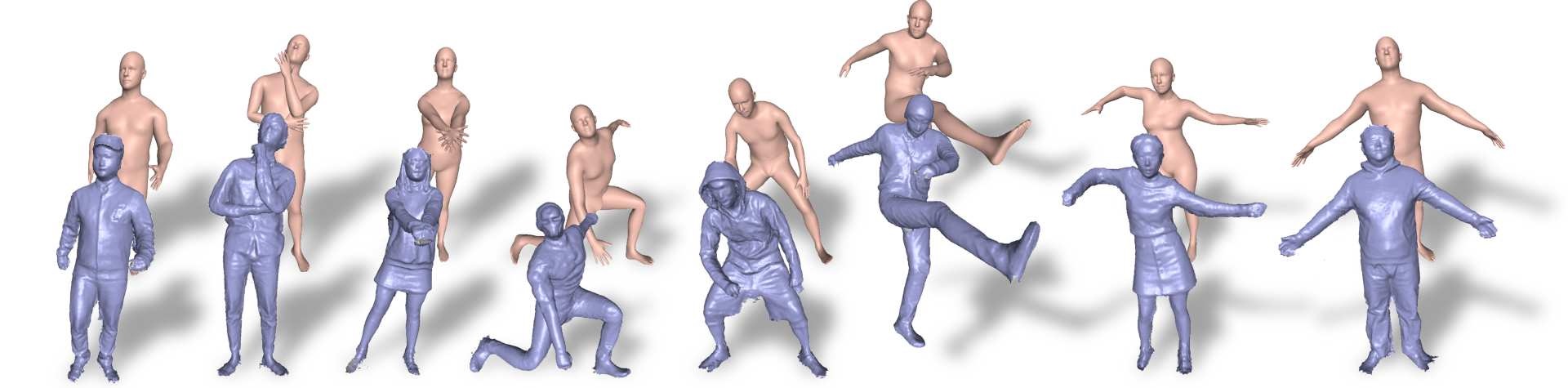 Hoodies, headphones, baggy clothes, nothing gets in the way of the all-seeing eye of DoubleFusion.
Hoodies, headphones, baggy clothes, nothing gets in the way of the all-seeing eye of DoubleFusion.
One shortcoming, however, is that it tends to overestimate a person’s body size if they’re wearing a lot of clothes — there’s no easy way for it to tell whether someone is broad or they are just wearing a chunky sweater. And it doesn’t work well when the person interacts with a separate object, like a table or game controller — it would likely try to interpret those as weird extensions of limbs. Handling these exceptions is planned for future work.
The paper’s first author is Tao Yu of Tsinghua University in China, but researchers from Beihang University, Google, USC, and the Max Planck Institute were also involved.
“We believe the robustness and accuracy of our approach will enable many applications, especially in AR/VR, gaming, entertainment and even virtual try-on as we also reconstruct the underlying body shape,” write the authors in the paper’s conclusion. “For the first time, with DoubleFusion, users can easily digitize themselves.”
There’s no use denying that there are lots of interesting applications of this technology. But there’s also no use denying that this technology is basically X-ray Spex.