
AWS today announced that its Neptune graph database, which made its debut during the platform’s annual re:Invent conference last November, is now generally available. The launch of Neptune was one of the dozens of announcements the company made during its annual developer event, so you can be forgiven if you missed it.
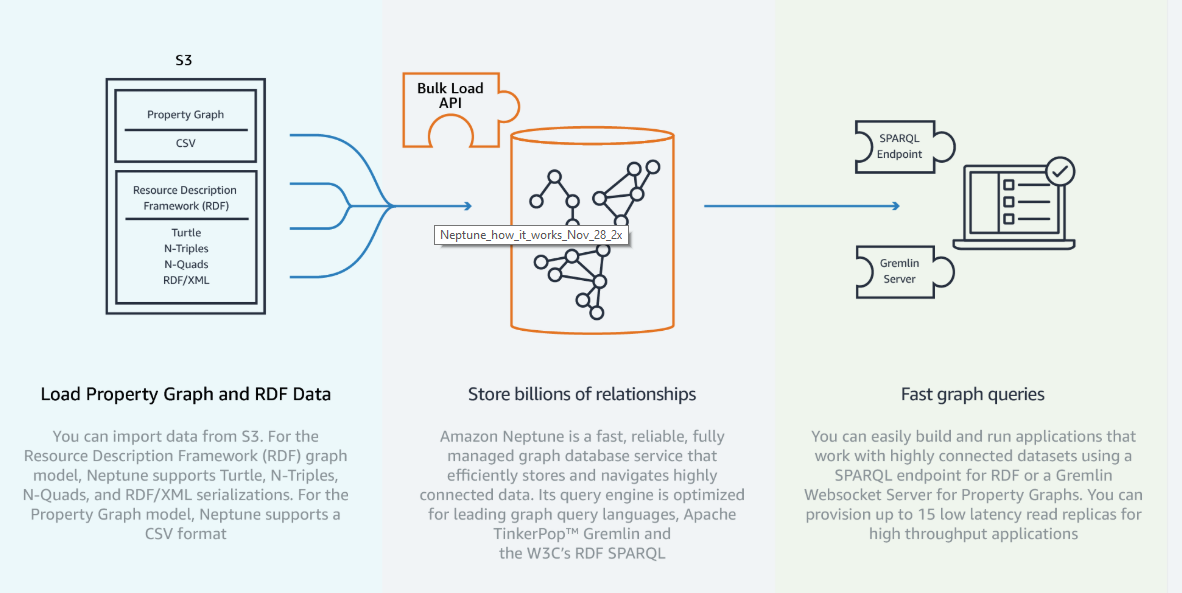
Neptune supports graph APIs for both TinkerPop Gremlin and SPARQL, making it compatible with a variety of applications. AWS notes that it built the service to recover from failures within 30 seconds and promises 99.99 percent availability.
“As the world has become more connected, applications that navigate large, connected data sets are increasingly more critical for customers,” said Raju Gulabani, vice president, Databases, Analytics, and Machine Learning at AWS. “We are delighted to give customers a high-performance graph database service that enables developers to query billions of relationships in milliseconds using standard APIs, making it easy to build and run applications that work with highly connected data sets.”
Standard use cases for Neptune are social networking applications, recommendation engines, fraud detection tools and networking applications that need to map the complex topology of an enterprise’s infrastructure.
Neptune already has a couple of high-profile users, including Samsung, AstraZeneca, Intuit, Siemens, Person, Thomson Reuters and Amazon’s own Alexa team. “Amazon Neptune is a key part of the toolkit we use to continually expand Alexa’s knowledge graph for our tens of millions of Alexa customers—it’s just Day 1 and we’re excited to continue our work with the AWS team to deliver even better experiences for our customers,” said David Hardcastle, director of Amazon Alexa, in today’s announcement.
The service is now available in AWS’s U.S. East (N. Virginia), U.S. East (Ohio), U.S. West (Oregon) and EU (Ireland) regions, with others coming online in the future.