
While it’s usually best to just sit back with a bucket of popcorn and watch reality business drama unfold, I was surprised by the severe reactions insinuating Facebook’s eagerness to profit at the expense of its users’ data, creating paranoia around data analytics and equating data driven targeting to an underhanded practice of mind control.
Perhaps this is because it’s being bundled up with the clearly unethical issues of fake news and foreign interference, both of which are distinct from the issue of data harvesting through Facebook’s API.
The scandal surrounding Facebook’s graph API 1.0 and 2.0 might not have been rooted in malicious intent. In fact, a key component of the solution lies in forming a shared understanding amongst platforms, regulators and users, of what data can reasonably be considered private.
“Facebook gave out its users data!”
Indeed it did. But it is important to gauge the motivation and intent behind doing this. For starters, this wasn’t a “leak” as many have called it. Graph API 1.0 was a conscious feature Facebook rolled out under its Platform vision to allow other developers to utilize Facebook data to give rise to presumably useful new apps and use-cases.
Core features of popular apps like Tinder, Timehop and various Zynga social games are powered by their ability to access users’ preexisting Facebook content, social connections and information, instead of having users build up that information from scratch for each app they use.
![]()
It was also not a “loophole”. Limitations and procedures for accessing data were clearly stated in the API’s documentation, available publicly for everyone to read. It did not hide the fact that a user’s friends’ data could also be accessed.
This was a product and architectural decision; and a bad decision in hindsight, because it lacked basic precautions against bad actors. But after all, this was API 1.0 and as with all first versions in the new agile world, there is always going to be significant learnings and course correction.
importantly, Facebook did not make any money from developers accessing data through the API. Therefore, the growing narrative insinuating some deceptive, profiteering motives with regards to user data does not resonate with me.
“Data is dangerous since it can be used for psychographic profiling in political campaigns!”
The media outcry has been sounding alarms and highlighting how data can be used to create segments and psychographic profiles to influence people with pinpoint precision. It’s important to realize that this is data-driven marketing and is not something new.
It has been a widely practiced and constantly improving marketing practice utilized across industries and even in political campaigns, across parties. To assume that it would not have happened if Facebook’s data was never accessible is incorrect.

In 2008 the Obama campaign used Facebook data to win the election.
The ability to capture data online and in the physical world is only getting better, and there is a growing industry whose core function is specifically capturing and selling data. The core issue here is neither the data source nor data analytics, but rather when a useful scientific tool has been used to add sophistication to an unethical or illegal activity.
Let’s elaborate using a simple example of a fictitious company ‘Homer Donuts’ which decides to run a series of ad campaigns for its different segments. For the price conscious segment their ad says “Homer Donuts is now 20% cheaper!”, for the health conscious segment it says “Try Homer Donuts’ new low-calorie airfried donuts!” and for the convenience conscious segment it says “Donuts delivered to your doorstep in 15 minutes“.
Understanding your target audience in granular segments and customizing your ad’s positioning, messaging and placement for each segment is a core part of data-driven marketing. None of this is wrong or manipulative. However, if they create a fake article titled “Homer donuts cures baldness! ” and show it as ads to us vulnerable bald folks, unless somehow miraculously true, that is fake news: intentionally and knowingly spreading false information in a way to mislead for benefit or towards an agenda.
Differentiation between the tools and the improper utilization is important lest businesses start having to feel apologetic and tentative in striving for advancements in data science and analytics.
The industry needs for a framework for shared responsibility on privacy
Facebook made a critical error of judgement in indiscriminately allowing anyone to access to conscenting users and that user’s entire list of friends. It was overly naive not to anticipate manipulation by bad actors and take precautionary measures. That said, it’s important to realize that it’s not in Facebook’s power alone to protect user data. There is need for a framework and shared understanding of privacy expectation levels amongst platforms, users and regulators to guide corporate practices, social behaviour and potential regulations.
Orkut (c. 2005) and Facebook (c. 2007) were my first exposure to social networks. I remember asking myself back then: Why would I write a message to a friend publicly on their “wall” instead of emailing them privately?
There needs to be a guiding principle on types of user data and the level to which a platform can utilize or analyze it.
The concept was completely alien and unintuitive to me at the time. And yet a short few years later wishing birthdays, sharing posts or writing a message to a friend in sight of a broader audience, whether to flaunt one’s friendship or to invite others to participate, became the new norm around the world. We tend to forget today that whereas services like chat messengers and email are varying degrees of private, things we write, post or share on social networks are varying degrees of public.
There needs to be a guiding principle on types of user data and the level to which a platform can utilize or analyze it. This level needs to be commensurate to the implicit privacy expectation based on where it is shared, the intended audience and the data’s purpose.
When Kim Kardashian shares a selfie on Instagram with her 109 million followers, it would unreasonable for her to be outraged if that photo finds its way into the hands of people outside of the platform. At a much smaller scale, when you share something with your social network of 500 friends and acquaintances, while it’s not technically public, you can’t reasonably expect it to be very private data.
It is very possible for anyone in that audience to further speak about, record or share your content with people outside your selected audience. Conversely, if you are having a private one-on-one chat with a person, your expectation and intent of privacy is a lot higher, despite the fact that it can still be shared on by that person.
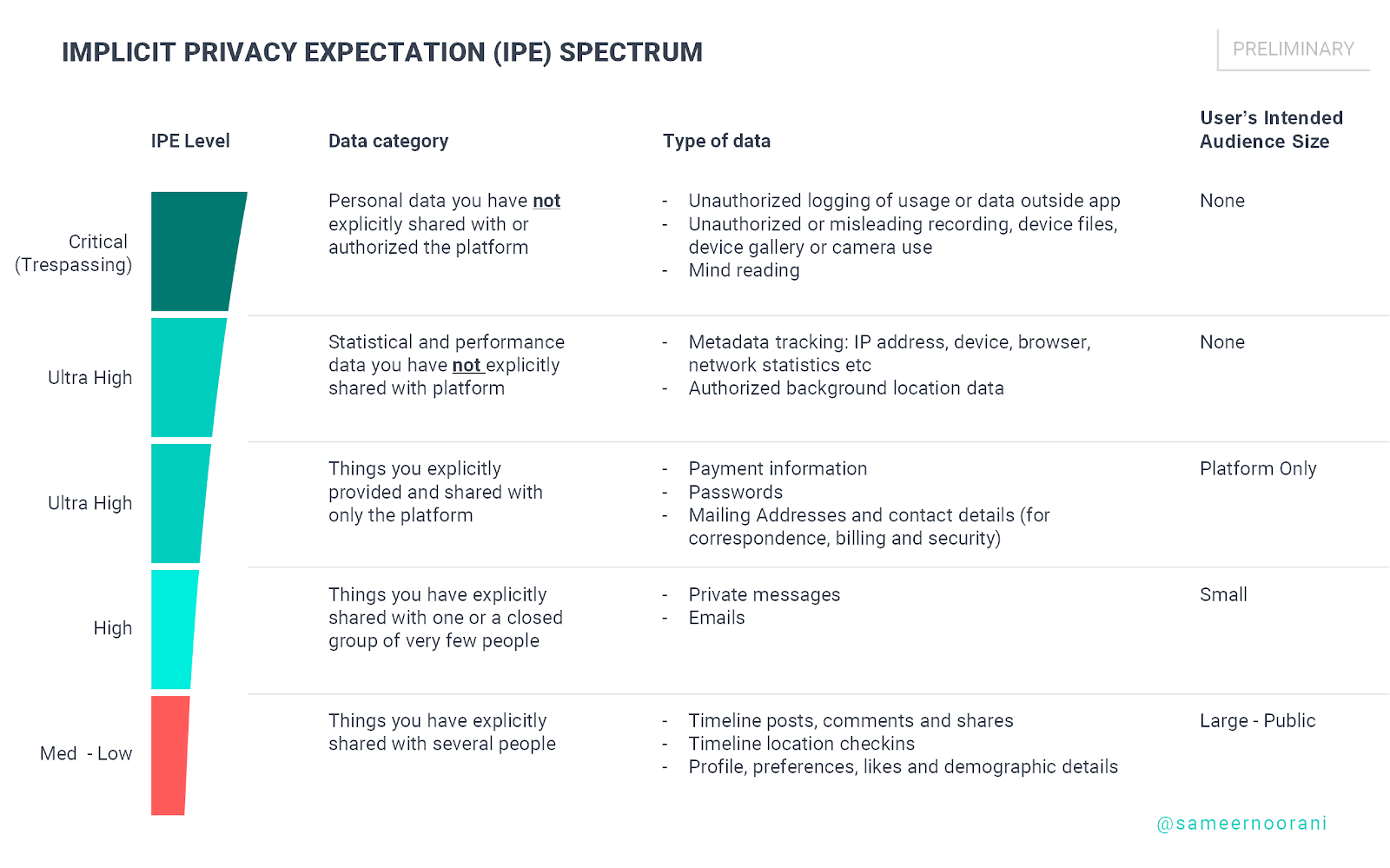
To illustrate this framework, let’s take the example of Facebook’s most criticized error in the data harvesting scandal: allowing users to be able to grant access to their friends’ information in addition to their own. Essentially, it would have been the equivalent of any user manually collecting all the data that he had rights to view on Facebook, be it his own, his friends’ or public content, and passing it on to the third-party app or whomever else he wishes.
So while Facebook added fuel to the fire by making it systematically easier and more effortless for a user to collect all this data and pass it on with a simple click of one button, the fire still exists; data can still be shared outside intended audiences even without the API’s provision.
The objective is not to absolve platforms of the responsibility to keep its users data safe, but to reinforce the understanding to all users that social networks by design cannot be foolproof data-safes and to adjust social media user’s norms in addition to counter those risks.
It is important to isolate and view all the different issues under consideration here. We are at a pivotal juncture in history where tech companies, regulators and lawmakers are actively reviewing the acceptability of evolved social norms. Along with addressing serious threats of fake news and foreign intervention, more granular and grey-area questions like what data should be considered private, the obligations of companies in protection of that data even if the data owner consents, and the acceptable boundaries of data-driven influencing in business and political settings must be debated taking all aspects, good and bad, into consideration.
Anyway, time to share this on Facebook.