Today Google announced a new labeled data set of human actions taking place in videos. That may sound obscure, but it’s a big deal for anyone working to solve problems in computer vision.
If you’ve been following along, you’ve noticed the significant uptick in companies building products and services that act as a second pair of human eyes. Video detectors like Matroid, security systems like Lighthouse and even autonomous cars benefit from an understanding of what’s going on inside a video, and that understanding is borne on the back of good labeled data sets for training and benchmarking.
Google’s AVA is short for atomic visual actions. In contrast to other data sets, it takes things up a notch by offering multiple labels for bounding boxes within relevant scenes. This adds more detail in complex scenes and makes for a more rigorous challenge for existing models.
In its blog post, Google does a great job explaining what makes human actions so difficult to classify. Actions, unlike static objects, unfold over time — simply put, there’s more uncertainty to solve for. A picture of someone running could actually just be a picture of someone jumping, but over time, as more and more frames are added, it becomes clear what is really happening. You can imagine how complicated things could get with two people interacting in a scene.
AVA consists of more than 57,000 video segments labeled with 96,000 labeled humans and 210,000 total labels. The video segments, pulled from public YouTube videos, are each three seconds long. These segments were then labeled manually using a potential list of 80 action types like walking, kicking or hugging.
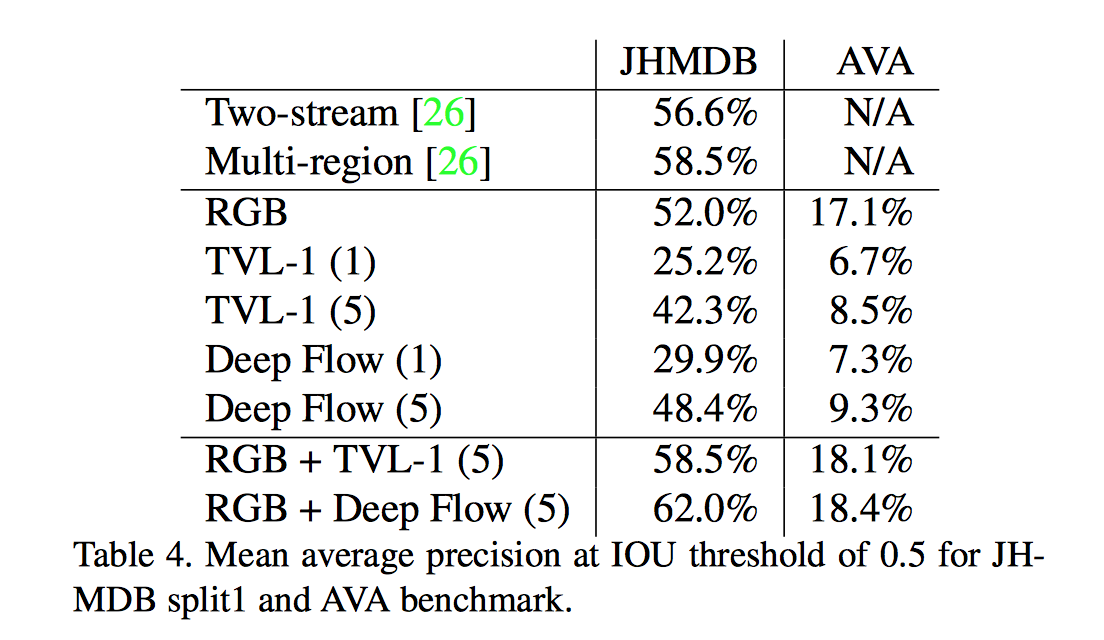
If you’re interested in tinkering, you can find the full data set here. Google first explained its efforts to create AVA in a paper that was published on arXiv back in May and updated in July. Initial experimentation covered in that paper showed that Google’s data set was incredibly difficult for existing classification techniques — displayed below as the contrast between performance on the older JHMDB data set and performance on the new AVA data set.