
Income inequality and disparity in resource distribution have drawn a lot of attention recently in the United States. Today, we’ll investigate a variation on the theme, exploring the distribution of a specific resource, venture capital funding, across a particular population, in this case, all U.S.-based technology companies founded in or after 2003 with at least one recorded funding round.
It’s intuitive that the majority of startup funding, in dollar terms, goes to a small number of companies. You can verify that by observing the difference between the large number of early-stage rounds closed, and their comparatively modest share of aggregate investment during any period.
But we are not content to merely declare that the majority of funding goes to a minority of companies. Today we will quantify it using a few standard analytical tools that will help us better understand the extent to which private-investment resources are distributed unequally among our cohort of startups.
Lines and curves and coefficients, oh my!
Despite being over a century old at this point, the tools we will use here are still the gold standard for measuring inequality. And what are the tools? Lorenz curves and Gini coefficients. Before we get to startup funding and its inequality — which, of course, is more feature than bug — let’s understand our curves and coefficients.
(Note to readers: If you have a good working knowledge of basic economic metrics, you can probably skip this section.)
Lorenz curves, which display the distribution of income or wealth in an economic system, are a way to “take account simultaneously of changes in wealth and changes in population” according to a paper Max O. Lorenz published in 1905.
A Lorenz curve is displayed as coordinates on a two-dimensional plane, where the X axis is the cumulative share of the population (from 0 to 100 percent) and the Y axis is the cumulative share of the income. The values plotted on that plane for the population one wants to analyze results in a Lorenz curve.
Below, we’ve rendered an example of several Lorenz curves.
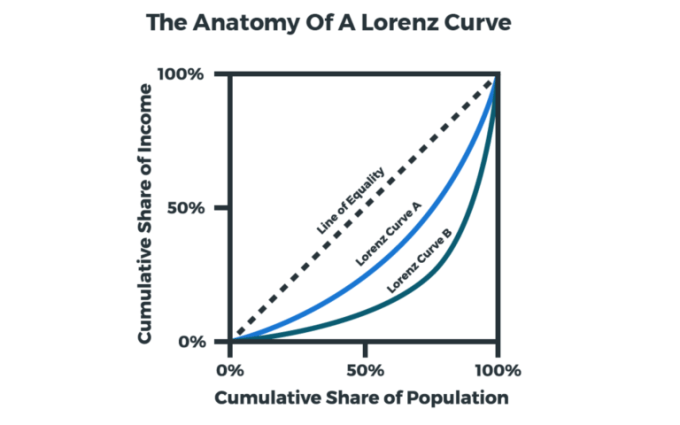
Typically, Lorenz curves also include a “Line of Equality,” a straight 45-degree line between the origin and the top-right corner of the plane. As the name suggests, the line shows what a totally equal distribution of wealth or income would look like, which serves as a point of comparison against the actual distribution of wealth displayed by the Lorenz curve.
Lorenz curves can be generated for populations of very different sizes and compositions. But because the terms on which the populations are compared are the same, you can overlay Lorenz curves to make some qualitative comparisons between different populations.
The more convex or “bowed out” the Lorenz curve, the more unequal the distribution of income, wealth or whatever else one is measuring. In the example above, the population represented by Lorenz Curve A has a more equal distribution of income than the population represented by Lorenz Curve B.
Lorenz curves can be used to make qualitative comparisons just based on appearance, but what about making quantitative comparisons? In 1912, Italian statistician Corrado Gini published a paper explaining how to measure the income or wealth distribution of a nation’s residents. This method takes the ratio of the area under a Lorenz curve and the area under the line of equality.
Let’s go back to our example diagram.
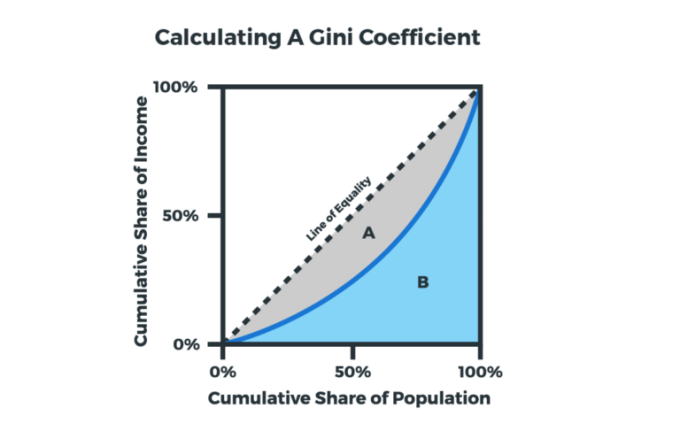
To calculate the Gini coefficient, we divide the Area A by the sum of Area A and Area B. So basically, Gini = A / (A+B). A Gini coefficient of 1 represents maximal inequality, whereas a Gini coefficient of 0 represents maximal equality.
Now, anyone who has taken calculus knows that the ideal way to find the area under a curve is to find the integral of the function, and, in this case, the function in question is the Lorenz curve. However, real-world data does not always fit so nicely into standard regression models, so finding the function that best fits the Lorenz curve can be difficult. Accordingly, finding the integral would be difficult, as well.
So, for our purposes here, we’ll just take the sum of the areas under the Lorenz curve by multiplying the mean height (on the Y axis) of each data point by the width taken up on the X axis. We’ll find that width by dividing 1 by the total number of data points in our sample set. (Example: For a sample set of 10 entities, the “width” of each data point would be 0.1.) Given that we’ll be using relatively large data sets here, our calculations will produce a reasonably accurate approximation of the integral of each Lorenz curve.
Now, back to startups.
Measuring inequality in U.S. startup funding
As we mentioned earlier, Lorenz curves and Gini coefficients are typically used to measure inequality in the distribution of income or wealth within a population. We thought it would be fun to calculate these statistics for startups in the United States.
We started with a data set of nearly 53,000 pre-IPO non-PE venture capital and venture debt deals struck with startups based in the United States that were founded in or after 2003, the time most consider the “Era of the Unicorn.” Importantly, this data set did not include companies from sectors like life sciences, oil and gas, energy and others with very high upfront startup costs or non-standard early-stage funding practices.
We then aggregated the deal data around companies’ unique IDs listed in the data set. This produced a list of nearly 24,700 companies and the total amount of funding recorded for each of them in Crunchbase’s database. We ranked the companies in descending order by the amount of total funding. We then calculated the percentage share of the population that company represents and the share of total funding each company has received.
We then plotted the data points on a chart to produce a Lorenz curve and a line of equality:
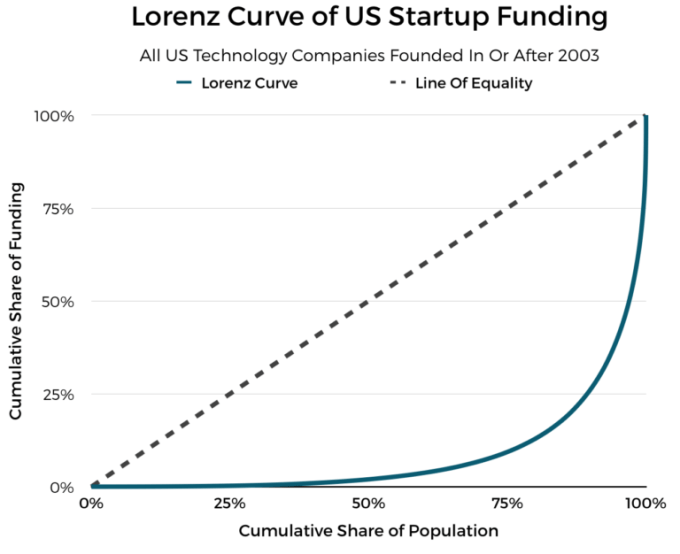
For investment data from ~24,700 companies, we found that the Gini coefficient is a whopping 0.836, according to our calculations.
If that’s the result for the entire country, what if we broke it out by metropolitan region, specifically the two largest (in terms of startup funding) and the rest of the country?
Out of the nearly 24,700 companies in our analysis, here’s how it broke down:
- ~6,600 are based in the San Francisco Bay Area and Silicon Valley (as defined by this list of cities and towns, which includes the likes of Oakland, Berkeley and San Jose).
- ~3,300 of them were based in the New York City metropolitan area (as defined by the list of cities and counties in this article).
- ~14,800 companies are located outside of these two metropolitan regions.
Before showing the Lorenz curve and related metrics, let’s see, in aggregate, how more than $650 billion in startup funding from the past 14 years breaks down between the two biggest hubs of startup funding activity compared to the rest of the country.
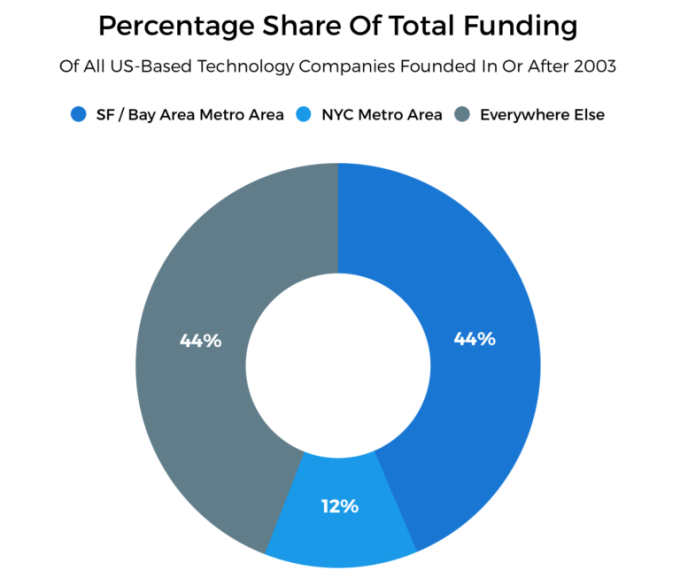
This donut chart shows the concentration of startup funding activity in San Francisco and surrounding municipalities. However, when we make an apples-to-apples comparison between the Bay Area, the NYC metro area and the rest of the United States, we see something more striking: There’s a fairly even distribution of startup funding within each regional population.
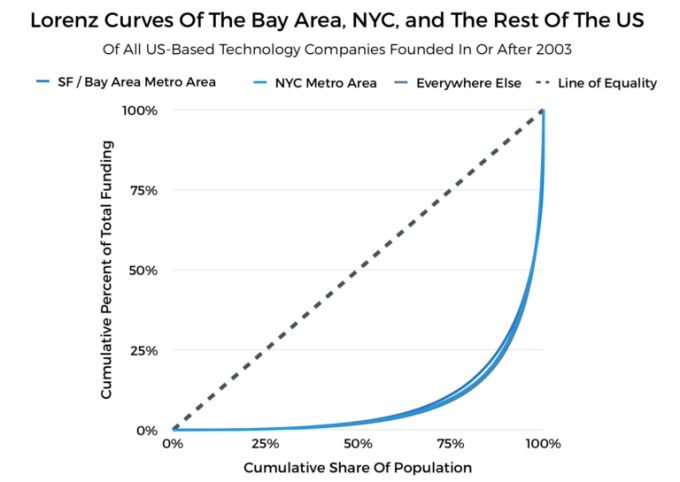
Although there is some slight variation between each population, in general, the distribution of startup funding between all the regions is remarkably even.
By this measurement, the SF Bay Area is marginally more egalitarian in its distribution than the NYC metro area, which is, in turn, more egalitarian than the rest of the USA. But, once again, this isn’t saying a whole lot.
On its face, this is expected. Here, we analyzed a large and mostly unfiltered data set. For example, things would have looked a bit different had we constrained our analysis to only those companies that raised a Series A round or beyond, or if we eliminated the companies that have, say, raised less than $50,000 in total funding.
It’s also not terribly surprising that there isn’t a huge variation between the two metro regions we looked at and the rest of the United States. Each population has a very small group of companies that have received the bulk of funding, as well as a very long tail of companies that have raised comparatively little money.
Unequal but okay
In the case of startup investment, there’s a tremendous incentive to heap capital upon “the winners” in hopes of generating the highest risk-adjusted returns. Discussions of “fairness” and “equitable division of resources” don’t gain traction in venture capital or other asset classes, and perhaps for good reason. If a minority of companies generate the majority of returns, nobody is going to cry foul that said companies received the overwhelming majority of funding.
To the winners go the spoils.