
The researchers over at OpenAI were able to use a recurrent mLSTM character-level model trained on Amazon reviews to identify the sentiment of blocks of text. And perhaps more interestingly, the team was able to generate new text with customizable sentiment.
Neither LSTMs nor sentiment analysis are new, but combining them in a way that reportedly breaks records for sentiment analysis accuracy on commonly used benchmarking data sets is worth note — particularly when you account for the efficiency of the models.
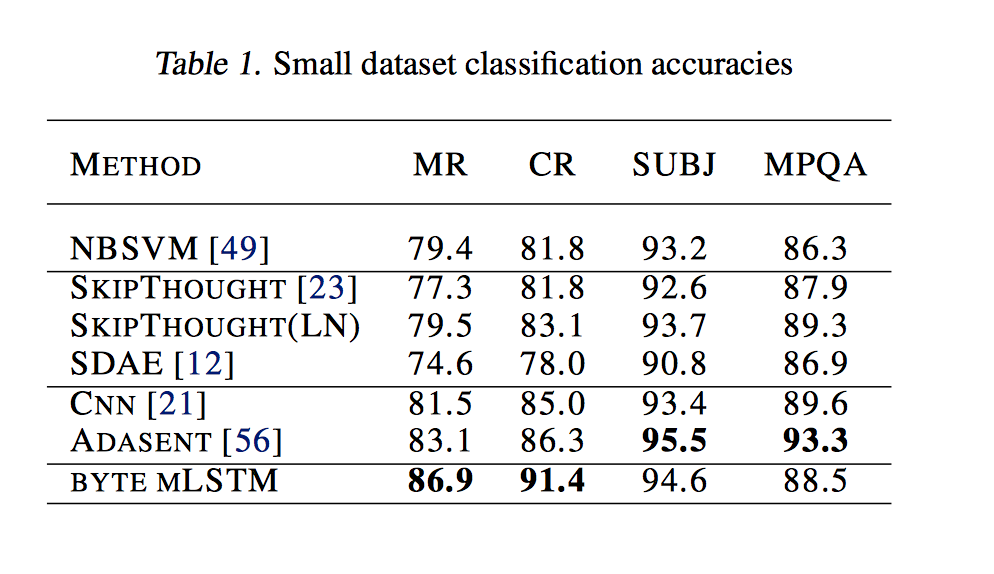 The team’s model only outperformed existing methods on two of four small text classification data sets, the MR and CR data sets. These data sets are made up of Rotten Tomatoes and Amazon product reviews. Meanwhile, OpenAI was unable to beat existing methods for the SUBJ and MPQA data sets. OpenAI says it can match performance with just a handful of labeled training examples.
The team’s model only outperformed existing methods on two of four small text classification data sets, the MR and CR data sets. These data sets are made up of Rotten Tomatoes and Amazon product reviews. Meanwhile, OpenAI was unable to beat existing methods for the SUBJ and MPQA data sets. OpenAI says it can match performance with just a handful of labeled training examples.
Because the model was trained to be generative, it was also able to output reviews with preset sentiments. The table below is pulled from the paper and shows a random assortment of examples for both positive and negative reviews.

These results are cool, but if you’re totally new to this, let’s take a few steps back. Even before machine learning, engineers interested in classifying sentiment would employ relatively dumb heuristics like keyword search to get the job done.
However, with these methods, a sentence like, “I hope you’re happy,” could easily be misinterpreted as having a positive connotation simply because it possesses the word happy. Context matters; what’s said before immediately impacts the meaning of what is said after. Clearly if that sentence was preceded by, “You killed him,” the interpretation would be different.
Machine learning approaches to sentiment have become commonplace for interpreting intent in conversational interfaces and making mood-appropriate product recommendations, among other things. More recently, LSTMs, or long short term memory recurrent neural networks, have drawn attention because of their ability to keep track of context over longer time intervals.
Andrej Karpathy, Justin Johnson and Fei-Fei Li’s work from 2015 on recurrent networks laid much of the groundwork for OpenAI’s paper. That team showed that LSTMs can keep track of text attributes like quotes, line lengths and brackets in interpretable cells.
Alec Radford, one of the three researchers who authored the OpenAI paper, explained to me in an email that because their model is operating at the character level, rather than the word level, documents can have 10,000 time stamps in them. Such a large time span can be a challenge for LSTMs. Generally, researchers have been able to get great results despite these limitations, but seeking perfection is another story.
“Functionally an LSTM is ‘leaky,’ ” explained Radford. “It never remembers things perfectly so even if you have a sentiment value of 1 and keep 0.999 of it at every timestep, you’re at 0.36 after 1000 timesteps.”
It’s hard to say at this point what other applications outside of sentiment this work could have. With unsupervised learning, it’s not easy to extrapolate what results might be obtained for other use cases.