
Two billion photos find their way onto Facebook’s family of apps every single day and the company is racing to understand them and their moving counterparts with the hope of increasing engagement. And while machine learning is undoubtedly the map to the treasure, Facebook and its competitors are still trying to work out how to deal with the spoils once they find them.
Facebook AI Similarity Search (FAISS), released as an open-source library last month, began as an internal research project to address bottlenecks slowing the process of identifying similar content once a user’s preferences are understood. Under the leadership of Yann LeCun, Facebook’s AI Research (FAIR) lab is making it possible for everyone to more quickly relate needles within a haystack.
On its own, training a machine learning model is already an incredibly intensive computational process. But a funny thing happens when machine learning models comb over videos, pictures and text — new information gets created! FAISS is able to efficiently search across billions of dimensions of data to identify similar content.
In an interview with TechCrunch, Jeff Johnson, one of the three FAIR researchers working on the project, emphasized that FAISS isn’t so much a fundamental AI advancement as it is a fundamental AI-enabling technique.
Imagine you wanted to perform object recognition on a public video that a user shared to understand its contents so you could serve up a relevant ad. First you’d have to train and run that algorithm on the video, coming up with a bunch of new data.
From that, let’s say you discover that your target user is a big fan of trucks, the outdoors and adventure. This is helpful, but it’s still hard to say what advertisement you should display — a rugged tent? An ATV? A Ford F-150?
To figure this out, you would want to create a vector representation of the video you analyzed and compare it to your corpus of advertisements with the intent of finding the most similar video. This process would require a similarity search, whereby vectors are compared in multi-dimensional space.
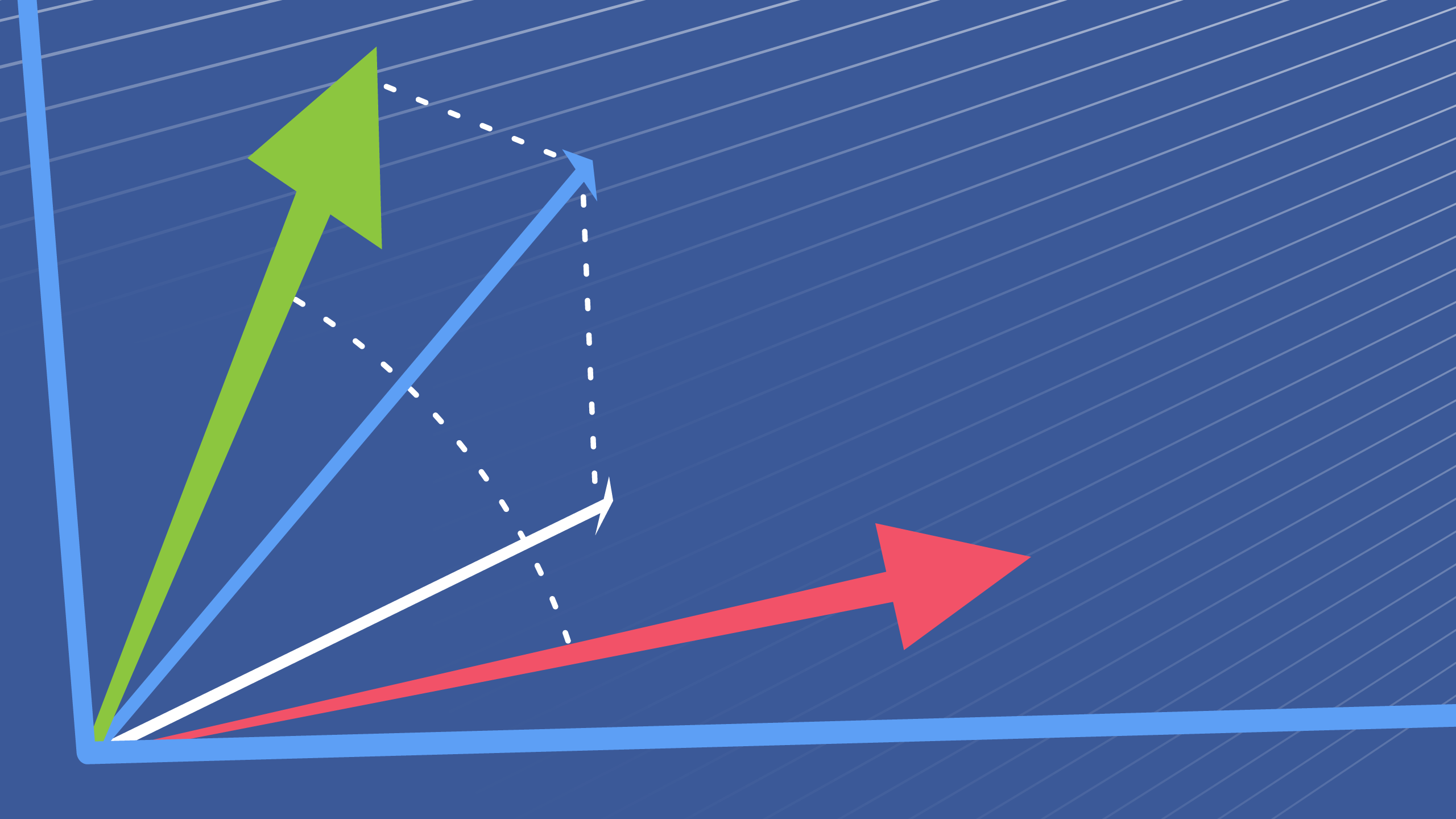
In this representation of a similarity search, the blue vector is the query. The distance between the “arrows” reflects their relative similarity.
In real life, the property of being an adventurous outdoorsy fan of trucks could constitute hundreds or even thousands of dimensions of information. Multiply this by the number of different videos you’re searching across and you can see why the library you implement for similarity search is important.
“At Facebook we have massive amounts of computing power and data and the question is how we can best take advantage of that by combining old and new techniques,” posited Johnson.
Facebook reports that implementing k-nearest neighbor across GPUs resulted in an 8.5x improvement in processing time. Within the previously explained vector space, nearest neighbor algorithms let us identify the most closely related vectors.
More efficient similarity search opens up possibilities for recommendation engines and personal assistants alike. Facebook M, its own intelligent assistant, relies on having humans in the loop to assist users. Facebook considers “M” to be a test bed to experiment with the relationship between humans and AI. LeCun noted that there are a number of domains within M where FAISS could be useful.
“An intelligent virtual assistant looking for an answer would need to look through a very long list,” LeCun explained to me. “Finding nearest neighbors is a very important functionality.”
Improved similarity search could support memory networks to help keep track of context and basic factual knowledge, LeCun continued. Short-term memory contrasts with learned skills like finding the optimal solution to a puzzle. In the future, a machine might be able to watch a video or read a story and then answer critical follow-up questions about it.
More broadly, FAISS could support more dynamic content on the platform. LeCun noted that news and memes change every day and better methods of searching content could drive better user experiences.
Two billion new photos a day presents Facebook with a billion and a half opportunities to better understand its users. Each and every fleeting chance at boosting engagement is dependent on being able to quickly and accurately sift through content and that means more than just tethering GPUs.