
Since Cloudflare revealed a bug that caused random chunks of data to leak from customer websites, including Fitbit and OkCupid, the company has worked to determine the extent of the problem. It turns out that the vulnerability caused extensive leaks — which isn’t much of a surprise, given the sheer number of websites that use Cloudflare for its security and performance features.
Although the investigation into the vulnerability, known as Cloudbleed, is still underway, Cloudflare estimated today that the bug causing data to leak was triggered 1,242,071 times between Sept. 22 and Feb. 18. The problem started slowly in September when Cloudflare first introduced a new HTML parser, initially affecting fewer than 180 websites. But as the parser was rolled out more widely in February, that number shot up to 6,457.
The leaked data was automatically cached by search engines, so Cloudflare has worked with Google, Bing, Yahoo, Baidu and other companies to scrub sensitive data from their caches. More than 80,000 cached pages have been deleted from various search engines. Although the majority of the data leaked came from Cloudflare headers, the company estimates that about half of the leaks contained cookies, some of which may have been session cookies that would allow an attacker to log in to a user’s account without their password.
“Given the scale of Cloudflare, the impact was potentially massive,” CEO Matthew Prince wrote in a recap of Cloudflare’s investigation. “We know we disappointed you and we apologize. We will continue to share what we discover because we believe trust is critical and transparency is the foundation of that trust.”
The numbers show that Cloudbleed posed a massive security risk — but Cloudflare has not yet found any evidence that the bug was discovered by anyone other than Google researcher Tavis Ormandy, who alerted Cloudflare to the problem.
Tracing the steps of Cloudbleed is difficult because of the nature of the bug. Unlike a normal breach, where sensitive data is extracted from a particular website, Cloudbleed caused random bits of memory that could have come from any of its millions of customers’ websites to get dumped at the bottom of a webpage.
An attacker could continuously send requests to the page, but there was no way to control the result — so he or she would receive a random mix of Cloudflare headers, cookies, tokens and other data. (So far, Cloudflare has not found any leaked passwords, credit cards, health records, Social Security numbers, or customer encryption keys.) Over time, an attacker could accumulate useful information, but most of what they might obtain would be junk.
Because an attacker would need to make requests over and over again, Cloudflare looked for unusual request spikes in its logs to determine whether an attacker exploited the bug. It also hunted for strange increases in requests from single IP addresses — a potential sign that an attacker had discovered and was testing the bug.
“We’ve seen approximately 150 Cloudflare customers’ data in the more than 80,000 cached pages we’ve purged from search engine caches. When data for a customer is present, we’ve reached out to the customer proactively to share the data that we’ve discovered and help them work to mitigate any impact,” Prince said.
Cloudflare produced a probabilistic model for companies to estimate their Cloudbleed risk. Sites that receive more requests are at higher risk, and the risk decreases for less popular sites.
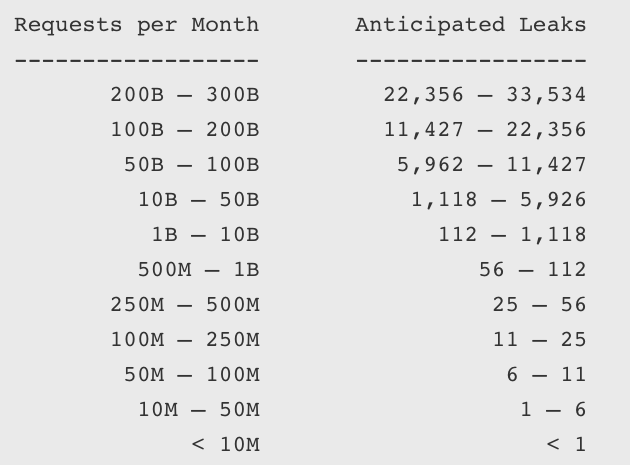
“Generally, if customer data was exposed, invalidating session cookies and rolling any internal authorization tokens is the best advice to mitigate the largest potential risk based on our investigation so far,” Prince explained.
Although Cloudflare hasn’t found any passwords in the leaks, some security experts have recommended that customers reset their passwords, just in case.