In recent years, we’ve seen an increasing number of so-called “intelligent” digital assistants being introduced on various devices. At the recent CES, both Hyundai and Toyota announced new in-car assistants. Although the technology behind these applications keeps getting better, there’s still a tendency for people to be disappointed by their capabilities — the expectation of “intelligence” is not being met.
Despite great strides in natural language processing (NLP) by data-driven approaches, natural language understanding remains elusive. The Winograd Schema Challenge is a recently proposed improvement on the Turing Test for assessing whether a machine can be judged “intelligent.” It’s named after Terry Winograd, who produced the first example of the type of pronoun disambiguation problem used in the challenge:
“The city councilmen refused the demonstrators a permit because they feared violence.”
What does the word “they” refer to here — the councilmen or the demonstrators? What if instead of “feared” we wrote “advocated?” This changes what we understand by the word “they.” Why? It is clear to us that councilmen are more likely to fear violence, whereas demonstrators are more likely to advocate it. This information, which is vital for disambiguating the pronoun “they,” is not in the text itself, which makes these problems extremely difficult for AI programs.
The first ever Winograd Schema Challenge was held last July, and the winning algorithm achieved a score on the challenge that was “a bit better than random.”
Representations versus understanding
There’s a technique for representing the words of a language that’s proving incredibly useful in many NLP tasks, such as sentiment analysis and machine translation. The representations are known as word embeddings, and they are mathematical representations of words that are trained from millions of examples of word usage in order to capture meaning. This is done by capturing relationships between words. To use a classic example, a good set of representations would capture the relationship “king is to man as queen is to woman” by ensuring that a particular mathematical relationship holds between the respective vectors (specifically, king – man + woman = queen).
Such vectorized representations are at the heart of Google’s new translation system, although they are representations of entire sentences, not just words. The new system “reduces translation errors by more than 55-85 percent on several major language pairs” and can perform zero-shot translation: translation between language pairs for which no training data exists.
Given all this, it may seem surprising to hear Oren Etzioni, a leading AI researcher with a particular focus on NLP, quip: When AI can’t determine what “it” refers to in a sentence, it’s hard to believe that it will take over the world.
So, AI can perform adequate translations between language pairs it was never trained on but it can’t determine what “it” refers to? How can this be?
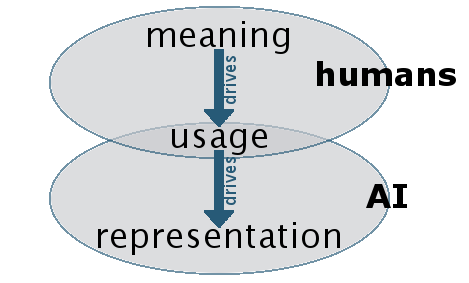
Meaning is only captured indirectly
When hearing about how vectorized representations of words and sentences work, it can be tempting to think they really are capturing meaning in the sense that there is some understanding happening. But this would be a mistake. The representations are derived from examples of language use. Our use of language is driven by meaning. Therefore, the derived representations naturally reflect that meaning. But the AI systems learning such representations have no direct access to actual meaning.
For the purposes of many NLP tasks, lack of access to actual meaning is not a serious problem.
Not understanding what “it” refers to in a sentence is not going to have an enormous effect on translation accuracy — it might mean “il” is used instead of “elle” when translating into French, but that’s probably not a big deal.
However, problems arise when trying to create a conversational AI:
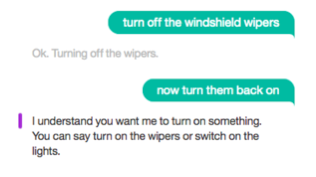
Screenshot from the sample bot you can create with IBM’s conversation service following this tutorial.
Understanding the referents of pronouns is a pretty important skill for holding conversations. As stated above, the training data used to train AIs that perform NLP tasks does not include the necessary information for disambiguating these words. That information comes from knowledge about the world. Whether it’s necessary to actually act as an embodied entity in the world or simply have vast amounts of “common sense knowledge” programmed in, to glean the necessary information is still an open question. Perhaps it’s something in-between.
Working within constraints
The problem of natural language understanding in AI is being worked on by some very smart people. At NIPS 2016, the biggest AI conference of the year, researchers at OpenAI presented A Paradigm for Situated and Goal-Driven Language Learning. Researchers at Stanford are looking into interactive language learning, an approach that recognizes the importance of interacting with the world in order to learn meaning. Interestingly, their example system pays homage to Terry Winograd’s SHRDLU system, an early conversational system that restricted itself to statements and questions about a world made up of blocks.
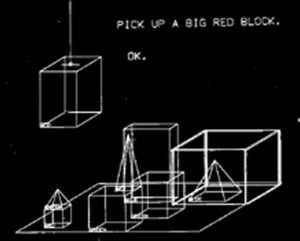
Terry Winograd’s early Natural Language Understanding program SHRDLU restricted itself to statements about a world made up of blocks. By Ksloniewski (Own work) CC BY-SA 4.0, via Wikimedia Commons
For anybody wanting to build a conversational AI today, such restrictions are still absolutely necessary. Both Amazon’s Lex and IBM’s conversation service work by allowing the developer to specify the constraints within which their app should work. They define a set of intentions that the app can carry out, and map to those intentions the set of possible ways a user might request them.
But there are ways of enhancing such conversational AI experiences even without solving natural language understanding (which may take decades, or longer). The image above showing a bot not understanding “now turn them back on” when the immediately prior request was “turn off the windshield wipers” demonstrates how disappointing it is when a totally unambiguous pronoun cannot be understood. That is definitely solvable with today’s technology.
Understanding what’s possible and what isn’t with today’s AI and machine learning capabilities is key for anyone looking to use such technology to build or enhance applications. If you’re not skeptical enough about claims being made about current capabilities, you could waste enormous amounts of time and money trying to do something that can’t (yet) be done. On the other hand, if you’re too skeptical, you risk missing opportunities to deploy today’s AI tech in incredibly useful and profitable ways.