Many of the largest companies in the world — like Facebook with FBLearner — have built an edge for themselves by making the process of studying their users and data science ongoing, tracking closely how things change over time. But for other businesses, those studies might just end with a single chart or predictive analysis report.
Ian Swanson started DataScience about two and a half years ago in order to provide those businesses with that kind of information. The company employed data scientists internally that would work with outside businesses. But over the past year, DataScience has been working to build an array of tools — ones that they’ve used internally — that businesses can hand to data scientists internally to essentially get the same thing done, which is launching today in the form of DataScience Cloud.
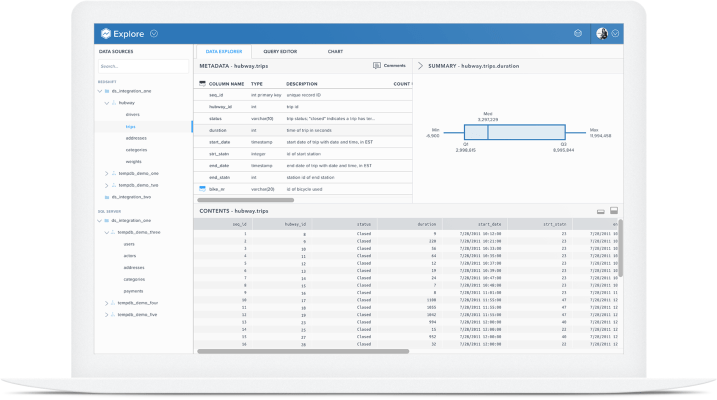
Here’s the short version: with DataScience Cloud, employees are able to look up a range of information across a wide array of sources — ranging from internal, unstructured databases to Salesforce accounts — with single SQL queries that have been optimized to work across all those buckets. They can then write predictive models for that data in the form of code, and deploy that code internally so other parts of the company can use to run simulations or additional tests against in order to better predict outcomes.
“Data scientist, and data science, is a pretty narrow focused term like a lot of roles: statistician, actuary, and so on,” Swanson said. “The common term we might hear is data science. They spend a lot of time performing engineering tasks, many times they fail to make an impact in their business. They might create from a simple standpoint some SQL queries, start to build a model using python or R, but once they create that model, one they can predict a user is leaving business, what do they do with it? You have to become algorithmic.”
Part of the challenge that led to DataScience was the process of actually building out those models. For example, it might be easier to put together a predictive model using Python, R or MATLAB for a data scientist, but it may need to be implemented in Java to be used across the organization. If the data scientist isn’t an expert in Java, that means handing the project over to an engineer to write through it in Java and not being able to make any adjustments to it without going through that engineer (or, of course, learning Java).
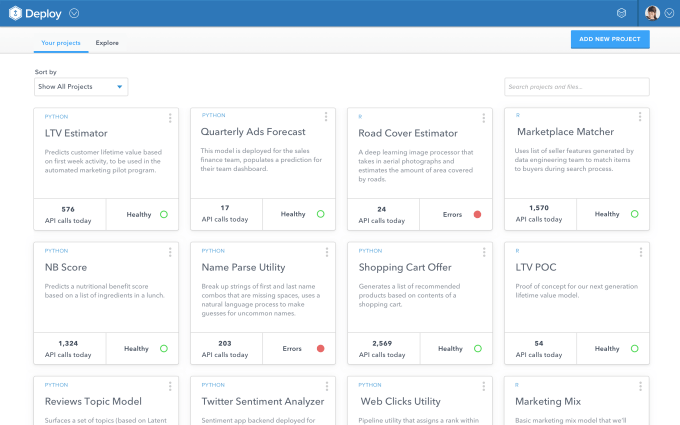
With this tool, data scientists can constantly tweak and update their models as new information comes in, as well as do it in the language they prefer. That keeps those teams more nimble and able to react more quickly to changes in the way people are using their tools. And it also means they have a better understanding of the scope of the models they can build and run, rather than there being a communicative disconnect between multiple departments in a company.
Another part of the problem was making sure that the query process was adaptable across multiple different skill sets, Swanson said. Because the role of “data scientist” is so overarching and becoming larger, there are a lot of roles that have expertise in small parts of the puzzle, and DataScience has to fill in the holes by making it easier to query the right information. Any queries done through DataScience can also operate on NoSQL databases as well. In the end, getting that data has to be fast, easy, and highly open to interpretation if it’s going to be a viable product for a large array of companies.
There are a couple of risks when it comes to a business like DataScience and a product like this. The main one is whether a company with a similar tool — or others with similar tools — would simply widely open source their tools in order to speed up the rate of development on them. That would allow other companies to start implementing those tools, and even start to build additional businesses on top of them.
Swanson’s argument against that is DataScience is handling the infrastructure side of things as well. Data science models often exist on servers that are constantly online, but aren’t always running those operations, he said, so that’s why the company has a pay-per-compute pricing model similar to what Amazon Web Services has.
DataScience has raised $28 million in funding total from Crosscut Ventures, Greycroft Partners and Whitehart Ventures.