
There is an array of neural net machine learning approaches that are simply more than just “deep.” In a time when neural networks are increasingly popular for advancing voice technologies and AI, it’s interesting that many of the current approaches were originally developed for image or video processing.
One of those methods, convolutional neural networks (CNNs), makes it easy to see why image-processing neural nets are strikingly similar to the way our brains process audio stimuli. CNNs, therefore, nicely illuminate that our audio and visual processes are connected in more ways than one.
What you need to know about CNNs
As human beings, we recognize a face or an object regardless of where in our visual field (or in a picture) it appears. When you try to model that capability in a machine, by teaching it how to search for visual features (like edges or curves at a lower level of a neural network or eyes and ears at a higher level, in the example of face recognition), you typically do so locally, as all relevant pixels are close to each other. In human visual perception, this is reflected by the fact that a cluster of neurons is focused on a small receptive field, which is part of the much larger entire visual field.
Because you don’t know where the relevant features will appear, you have to scan the entire visual field, either sequentially, sliding your small receptive field as a window over it (top to bottom and left to right) or have multiple smaller receptive fields (clusters of neurons) that each focus on (overlapping) small parts of the input.
The latter is what CNNs do. Together, these receptive fields cover the entire input and are called “convolutions.” Higher levels of the CNNs then condense the information coming from the individual lower-level convolutions and abstract away from the specific location, as shown below.
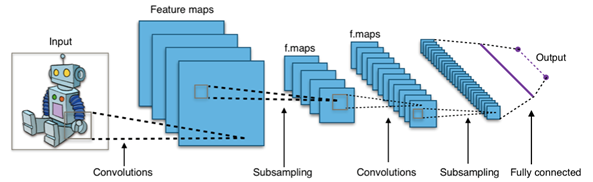
Source: Wikipedia
So, if you search for faces or objects in your photos using Google Photos, or the equivalent new feature in Apple’s iOS 10, you can assume that CNNs are at use for identifying the relevant candidate locations in pictures where the requested face or object might be shown.

Source: Region-based Convolutional Networks for Accurate Object Detection and Segmentation by Ross Girshick, Jeff Donahue, Trevor Darrell and Jitendra Malik
But we have also found several applications of CNNs to speech and language.
CNNs can be applied to a raw speech signal in an end-to-end way (i.e. without manual definition of features). The CNNs look at the speech signal by unfolding an input field with time as one dimension and the energy distribution over the various frequencies as the second dimension into their “convolutions,” thereby learning automatically which frequency bands are most relevant for speech. The higher layers of the network are then used for the core task of speech recognition: finding phonemes and words in the speech signal.
It has been shown that brain areas designed for the processing of audio signals and speech can be used for visual tasks.
Once you have those words, the next example is “intent classification” in natural language understanding (NLU), or understanding from a user request what type of task the user wants to achieve (I covered in a recent blog post how the other aspect of NLU, named entity recognition, works). For example, in the command “Transfer money from my checking account to John Smith,” the intent would be “money_transfer.” The intent is typically signaled by a word or a group of words (usually local to each other), which can appear anywhere in the query.
So, in analogy to image recognition we need to search for a local feature by sliding a window over a temporal phenomenon (the utterance; looking at one word and its context at a time) rather than a spatial field. And this works very well: When we introduced CNNs for this task, they performed more than 10 percent more accurately than the previous technology.
Neighbors in the brain — and in the field
Why are CNNs successful at these tasks? A rather straightforward explanation could be that they just share characteristics with image processing; they are all of the “find something small in something bigger, and we don’t know where it might be” type. But there may be another slightly more interesting explanation, namely the fact that CNNs designed for visual tasks also work for speech-related tasks, which is a reflection of the fact that the brain uses very similar methods to process both visual and audio/speech stimuli.
Consider phenomena like synesthesia, or the “stimulation of one sensory or cognitive pathway lead[ing] to automatic, involuntary experiences in a second sensory or cognitive pathway.” For example, audio or speech stimuli can lead to a visual reaction. (I employ a mild version of this; for me, each day of the week, or rather the word describing the day, has a distinct color. Monday is dark red, Tuesday grey, Wednesday a darker grey and Thursday a lighter red and so on.) It is being interpreted as an indication that processing of audio and speech signals and optical processing have to be so-called “neighbors” in the brain somehow.
Similarly, it has been shown that brain areas designed for the processing of audio signals and speech can be used for visual tasks, such as people born with hearing impairments who can re-purpose the audio/speech area of their brains to process sign language. This probably means that the organization of brain cells (neurons) processing visual or audio signals must be very similar.
So, back to the practical applications of all of this. It is not too difficult to imagine yourself a couple of years from now sitting in a self-driving car and chatting with an automated assistant asking it to play your favorite music or to book a table at a restaurant. There will likely be several CNNs active “behind the scenes” to make this work:
- One or several will be used by the LIDAR system (“Light detection and ranging,” a kind of radar based on lasers) used by the car to create a model of its surroundings, including obstacles and other cars.
- Likely the car will also use cameras to detect and interpret traffic signs; chances are good that CNNs will be used for that, as well.
- The automated assistant will use CNNs, both in its speech recognition and its natural language understanding components, to find phonemes and words in the speech signal and to find concepts in the stream of words, respectively.
And there will probably be others. Of course, all these tasks are performed by different CNNs, probably even in different control units. And each of the CNNs can only perform exactly the task for which it was trained, and none of the others (it would have to be retrained for that).
You could say the new developments in computer gaming helped to make the training of deep neural nets feasible.
However — and here it gets fascinating again — it has been shown that when CNNs are trained, they seem to acquire (especially on the lower layers) somewhat generic features (or concepts you could say) that carry over to other tasks. It is easy to see why this works for related domains; for example, in speech recognition you can take a CNN trained on one language (say English) and only re-train the top layers on another language (say German) and it will work well on that new language. Obviously the lower layers capture something that is common between multiple languages.
However — and I find it more surprising — it also has been tried to train CNNs across modalities, such as images of a scene and textual representations of that scene. The resulting networks can then be used to retrieve images based on text and vice versa. The authors conclude that at some level the CNNs learn features common to the modalities — without being told how to do so. Again, an interesting result demonstrating that seeing and dealing with language (text) must have a lot in common.
There also is another very practical ramification of the similarity of visual and audio/speech and language processing. We have found that graphical processing units (GPUs), which were developed for computer graphics (visual channel), can be employed to speed up machine learning tasks for speech and language, too. The reason is that the tasks that need to be handled again are similar in nature: applying relatively simple mathematical operations to lots of data points in parallel. So you could say the new developments in computer gaming helped to make the training of deep neural nets feasible.
Neural net research and innovation has broad implications, and, as we have seen, progress in one application area (like image recognition) also helps advance things in other areas (like speech recognition and NLU). As we have also seen, this may be caused by the many parallels between audio and visual receptors in the human brain, or in general how the brain is organized.
As a result, we will continue to see fast progress of machine learning and AI in many fields, all benefiting from research efforts in many areas whose results can be shared. More specifically, it is no longer a surprise that CNNs, originally designed for vision, will ultimately help machines to listen and better understand us — something that’s crucial as we are continually propelled forward into this new era of human-machine interaction.