
Application intelligence is the process of using machine learning technology to create apps that use historical and real-time data to make predictions and decisions to deliver rich, adaptive, personalized experiences for users.
We believe that every successful new application built today will be an intelligent application.
The armies of chat bots and virtual assistants, the e-commerce sites that show the right recommendations at the right time and the latest dating apps are all built to learn and create continuously improving experiences.
In addition, legacy applications are becoming more and more intelligent to compete and keep pace with this new wave of applications.
Now is an exciting time to be investing in the broader intelligent app ecosystem because several important trends are coming together in application development:
- The availability of massive computational power and low-cost storage to feed machine learning models,
- The ease of use with which developers can take advantage of machine learning techniques,
- The adoption of microservices as a development paradigm for applications, and
- The proliferation of platforms on which to develop applications, and in particular platforms based on “natural user interfaces” like messaging and voice.
We have spent time thinking about the various ways intelligent apps emerge — and how they are built.
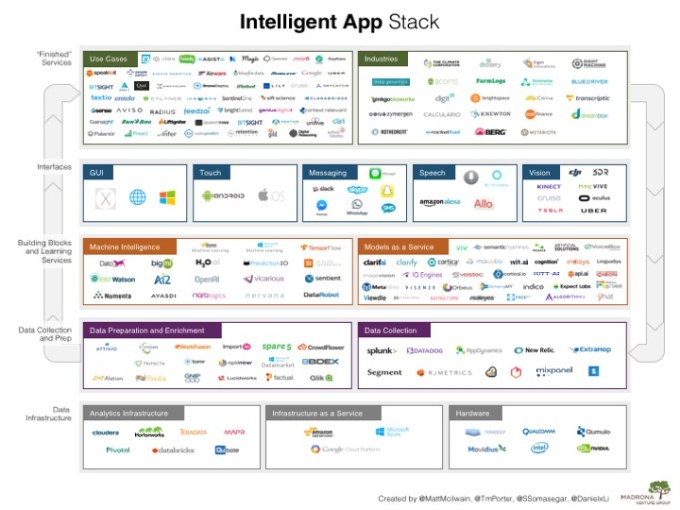
This intelligent app stack illustrates the various layers of technology that are crucial to the creation of intelligent apps.
As investors, we like to think about the market dynamics of major industry shifts, and the rise of intelligent apps will certainly create many new opportunities for startups and large technology companies alike.
Here are some of our thoughts on the key implications for companies operating at various layers of the intelligent app stack:
“Finished Services”
Applications will define the end user’s experience with machine learning

At the application layer there will be two primary classes of applications: net-new apps that are enabled by application intelligence and existing apps that are improved by application intelligence.
Net-new apps will need to solve the tough problem of determining how much end users will pay for “artificial intelligence” and how to ensure they capture a portion of the value delivered to users. More broadly, it will be interesting to see if our thesis that the value proposition of machine learning will primarily be a revenue generator comes true.
Also, because of the importance of high-quality, relevant data for machine learning models, we think that industry-specific applications or applications for specialized uses will present the most immediate pockets of opportunity at the Finished Services or application layer.
Today, we see the main categories of use-case-specific applications as autonomous systems, security and anomaly detection, sales and marketing optimization and personal assistants. We are also seeing a number of interesting vertically focused intelligent applications, especially serving the retail, healthcare, agriculture, financial services and biotech industries.
The killer apps of the last generation were built by companies like Amazon for e-commerce, Google for search and advertising, Facebook for social, Uber for transportation and Netflix for entertainment.
These companies have a significant head-start in machine learning and user data, but we believe there will be apps that are built from the ground up to be more intelligent that can win in these categories and new categories that are enabled by application intelligence.
Interfaces
New interfaces will transform applications into cross-platform “macro-services”

Image: Warner Bros. Entertainment
As we think about how new intelligent applications will be developed, one significant approach will be the transformation of an “app” to a service or experience that can be delivered over any number of interfaces. For example, we will see companies like Uber build “services” that can be delivered via an app, via the web and/or via a voice interface.
It will also be easier for companies to deliver their services across platforms as they design their apps using a microservices paradigm, where adding a new platform integration might be as simple as adding a new API layer that connects to all of the existing microservices for authentication, product catalog, inventory, recommendations and other functions.
The proliferation of new platforms such as Slack, Facebook Messenger, Alexa and VR stores will also be beneficial for developers because platforms will become more open, add features that make developers’ lives easier and compete for attention with offerings such as investment funds.
Finally, at the interface layer, we see the “natural interfaces” of text, speech and vision unlocking new categories such as conversational commerce and AR/VR. We are incredibly optimistic about the future of these interfaces, as these are the ways that humans interact with one another and with the world.
Building Blocks and Learning Services
Intelligent building blocks and learning services will be the brains behind apps
As companies adopt the microservices development paradigm, the ability to plug and play different machine learning models and services to deliver specific functionality becomes more and more interesting. The two categories of companies we see at this layer are the providers of raw machine intelligence and the providers of trained models or “Models as a Service.”
In the first category, companies provide the “primitives” or core building blocks for developers to build intelligent apps, like algorithms and deployment processes. In the second category, we see intermediate services that allow companies to plug and play pre-trained models for tasks like image tagging, natural language processing or product recommendations.
These two categories of companies provide a large portion of the value behind intelligent apps, but the key question for this layer will be how to ensure these building blocks can capture a portion of the value they are delivering to end users.
IBM Watson’s approach to this is to provide developer access to its APIs for free but charge a 30 percent revenue share when the app is released to customers. Others are charging based on API calls, compute time or virtual machines.
The key differentiators for companies in this layer will be the ability to provide a great user experience for developers and the accuracy and performance of machine leaning algorithms and models.
For complicated, but general problems like natural language understanding, it will likely be easier and more performant to use a pre-built model from a provider that specializes in generating the best data, models and processes. However, for specialized, business-specific problems, startups and enterprises will need to build their own models and data sets.
Data Collection and Prep
The difficult and boring tasks of data collection and preparation will get smarter
Before data is ready to be fed into a machine intelligence workflow or model, it needs to be collected, aggregated, cleaned and prepped. Sources of data for consumer and enterprise apps include photos and video, websites and text, customer behavior data, IT operations data, IoT sensor data and data from the web.
After applications are instrumented to collect the right pieces of raw data, the data needs to be transformed into a machine-ready format. For example, companies will need to take unstructured data like text documents and photos and transform it into structured data (think of rows and columns) that is ready for a machine to review.
The important part of this step is realizing that the quality of a model is highly dependent on the quality of its input data. Creating bots or “artificial intelligences” without high-quality training data can lead to unintended consequences (see Microsoft’s Tay), and the creation of this training data often relies on semi-manual processes like crowdsourcing or finding historical data sets.
The other area of this space to keep an eye on is the companies that have traditionally served as “dumb” pipes for data sources like clickstream data or application performance logs. Not only will they try to build predictive and adaptive features, they will also see competition from intelligent services that draw insights from the same data sources.
This will be an area of innovation for finance, CRM, IT Ops, marketing, HR and other key business functions that have traditionally collected data without receiving immediate insights. For example, HR software will become better at providing feedback for interviewers and highlighting the best candidates for a position based on historical data from previous hires.
Data Infrastructure
Intelligent apps will be built on the big data technology stack

Image: Flickr/Marius B under a CC by 2.0 license
The amount of data in the world is doubling every 18 months, and thanks to this explosion in big data, enterprises have invested heavily in storage and data analysis technologies.
Projects like Hadoop and Spark have been some of the key enablers for the larger application intelligence ecosystem, and they will continue to play a key role in the intelligent app stack. Open source will remain an important feature for choosing an analytics infrastructure because customers want to see what is “under the hood” and avoid vendor lock in when choosing where and how to store their data.
Within the IaaS bucket, each of the major cloud providers will compete to run the workloads that power intelligent apps. Already we are seeing companies open source key areas of IP such as Google’s TensorFlow ML platform, in a bid to attract companies and developers to their platform. Google, in particular, will be an interesting company to watch as it gives users access to its machine learning models, trained on some of the world’s largest data sets, to grow their core IaaS business.
Finally, hardware companies that specialize in storing and managing the massive amount of photos, videos, logs, transactions and IoT data will be critical to help businesses keep up with the new data generated by intelligent applications.
We think there will be value captured at all layers of this stack, and there is the opportunity to build significant winner-take-all businesses as the machine learning flywheel takes off. In the world of intelligent applications, data will be king, and the services that can generate the highest-quality data will have an unfair advantage from their data flywheel — more data leading to better models, leading to a better user experience, leading to more users, leading to more data.
Ten years from now, the vast majority of applications will be intelligent, and machine learning will be as important as the cloud has been for the last 10 years. Companies that dive in now and embrace intelligent applications will have a significant competitive advantage in building the most compelling experiences and the most valuable businesses.