
I dare say nobody wants to be the target of malicious hackers, and certainly doesn’t want private data out there in the hands of unknown third parties.
As individuals, we keep secret our most personal information — bank accounts, passwords and medical information — because we know it can be used against us. We trust organizations to keep this and other personally identifiable information (PII) private.
Of course, the same goes for the enterprise. Not only do enterprise companies hold large quantities of PII, they also possess intellectual property and proprietary information that they must keep close to the vest or face dire and potentially company-ending consequences.
Still, sometimes sharing some personal or internal data is desirable. For example, we’re willing to share information about our musical tastes because the data can be used to help us find new albums, and there is certainly value in having credit card companies exchange otherwise confidential information in order to spot fraud.
Some data held by private companies or governments is of value to researchers, and releasing it can be for the public good. One excellent example is Yahoo’s offer of the largest machine learning data set in history, taken from its own internal user activity logs.
This raises the question: What sharing is permitted and who decides where to draw the line on our behalf? There is a new threat to our ability to control the answer to this question, with which data scientists must now also contend. Surprisingly, this emerging villain is also the hero of the big data age: machine learning.
Fuzzy matching, fuzzy leaks
Machine learning seems sometimes to produce something out of nothing — like reading between the lines — but the information is actually there in the data, it’s just latent.
However, machine learning, while brilliant, can also mean bad news for even the most secure and well-intentioned enterprise that carefully shares data for all the right reasons. Alongside the shared data there may also be leaking some other, unintended, information, making data leakages not as black and white as they once were. What results are “fuzzy” data leaks.
We may simply have to expect that releasing some personal information makes it theoretically possible that we’re releasing more.
Even the concept of “personally identifiable” data has become a fuzzier idea. For example, Netflix famously sponsored a $1 million prize to the team that could build the best movie recommender using its data. It purposely shared its viewing data, which contained no explicit personal information at all. However, it was quickly cross-referenced with other public data to reliably discover the identity of many people in the data set. Certainly, more was shared than was obvious to anyone, and, in this case, it resulted in a lawsuit.
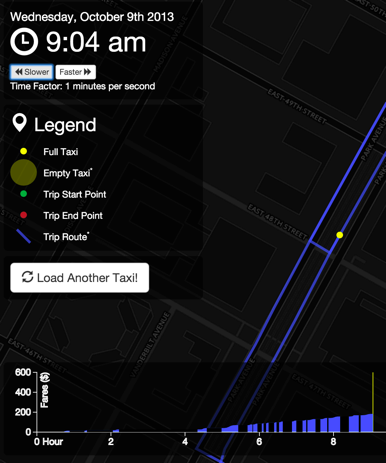
In 2013, New York City released records of taxi rides in the city, including the timing and location of trips and fares. It obscured the true taxi medallion number to protect the identity of the driver. However, it was done in a simplistic way, with an MD5 hash (MD5 hashing is a standard way to produce a short opaque “fingerprint” from a value in a — usually — virtually irreversible way). It turned out that this was easily reversed.
It wasn’t long before the taxi medallion IDs were cross-referenced with photos of celebrities entering and exiting the vehicles. Once time and location data was added, it became simple to discover the destination of the taxi — even the tip. Both were embarrassing in a few cases. And this was already technically public information! The availability of other data combined with computing power is what exposed the issue.
In fact, the data can be effortlessly explored here, as shown below.
The list goes on:
- “Anonymous” transactions in bitcoin were traced reliably to an IP address.
- 87 percent of the U.S. population is actually uniquely identified by ZIP code, gender and date of birth.
- Target figured out a teen girl was pregnant before her father did (based on purchases) — and kindly sent maternity-themed coupons to their home.
- We may implicitly build decision processes that reinforce gender or race stereotypes, which inadvertently use this information in cases where it was neither disclosed nor collected directly.
Security in an age of machine learning
What can we do to stop fuzzy data leaks? We will need to take a couple of steps into account to better thwart the danger of fuzzy data leakage.
First: Keep priorities straight. Deploying proper encryption, authorization and authentication remain an essential foundation. In fact, this is the law in most industries that handle sensitive information like healthcare (see HIPAA in the United States) and finance (a significant part of Sarbanes-Oxley). Most data leaks are still the clear-cut, old-fashioned kind — data was accessed by someone explicitly not authorized to use it, whether an outsider or insider.
Second: Greater awareness of the problem and potential solutions amongst data scientists should help. For example, the Netflix data set could have further obscured user identity by adding noise, permuting ordering and removing some activity at random, without noticeably compromising the result.
The NYC taxi data set would have remained as anonymized as intended with a simple salting of medallion numbers input to an MD5 hash. (salting, or just adding a short value before hashing, defeats common ways to reverse the hash.) In the end, we may have to learn to design collection and decision processes to not silently encode latent information we are not entitled to know.
Finally: There is an aspect of this that will rely on transparency. We don’t want to stop sharing data completely or legislate away the use of any data. In the end, consumers must have an understanding of which of their data are being used when and by whom, and also understand how it benefits them and what risks of leak this poses.
We may simply have to expect that releasing some personal information makes it theoretically possible that we’re releasing more, and adjust our behavior accordingly. With transparency about usage, and with increasing control over it, individuals will vote with their data for the right risk-adjusted kinds of usages.