
Editor’s note: Derrick Harris is a senior research analyst at Mesosphere. Harris most recently covered cloud and big data new for GigaOM.
The Internet has changed a lot about people’s lives in the past couple decades. Web and mobile applications let us search for information, buy products, and communicate frictionlessly, from anywhere — at speeds and in ways never before possible. We get movie recommendations on the dashboards of our cars, produce and publish videos on our phones, and buy thermostats that predict when we will be at work so they can turn down the heat.
While these advances might seem like magic to the outside world, the people building these applications understand just how much has gone into making them work. However, with each passing day, it’s increasingly important for everyone in the business world to understand this, too.
The reason is simple: smart companies understand that competing in the next decade will require new ways of thinking about IT. Everything from mobile apps to refrigerators will need to be more personalized, more intelligent and more responsive. Companies will need the tools in place to do machine learning, ingest sensor data and handle unexpected surges in user traffic without going down.
There is no going back. If an application can’t deliver the experience users expect, they’ll find another one that does.
Reinventing How Applications Are Built
As usage of applications and websites scaled into the millions (or billions) of users over the past several years, previous eras of application architecture began to break down under the sheer volume of traffic and user data. More recently, a desire to make greater use of incredible amounts of available digital data has sparked interest in an entirely new class of technologies aimed at that end alone.
The solution to these problems has often involved the creation of new storage, processing and database frameworks designed to easily scale across clusters of servers, and to simplify the process and speed of moving information between the pieces.The same general patterns repeat time after time at places like Google, LinkedIn, Facebook, Yahoo and Twitter.
One of these patterns happened at the database layer, where nearly everyone started out with a relational database and eventually had to figure out a new plan. Some companies spent (and continue to spend) untold millions of dollars and person-hours making MySQL scale beyond its natural limits. Some created new database technologies. Some did both.
Another area where a clear pattern emerged was in architectures for processing big data. The specific technologies might differ from place to place, but every large web company has some sort of architecture in place for handling real-time, near-real-time and batch data processing. They want to be able deliver fast, personalized experiences to customers where necessary, and also make sure internal data analysts and data scientists have what they need to do their jobs.
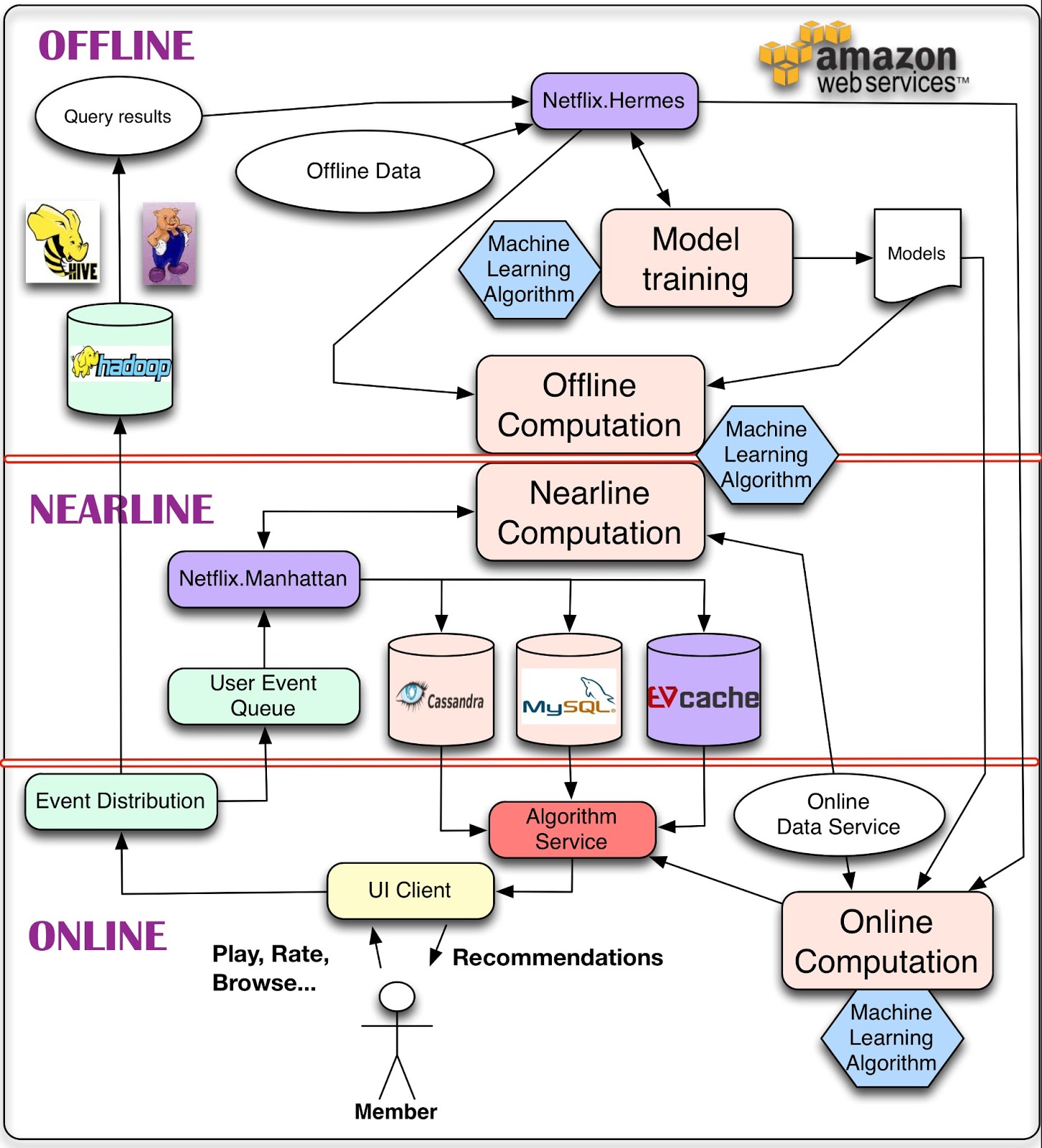
Meet the Data Center Application Stack
The results of all this IT innovation have been impressive. Google, Facebook and Amazon serve billions of users overall — and many, many millions concurrently — and store incredible amounts of data. Yet they rarely crash. Once it finally decided to make a significant investment in infrastructure engineering, Twitter all but slayed the fail whale.
Among some of the better-known technologies these companies have produced are MapReduce, Hadoop, Cassandra and Kafka. A new suite of tools — some created by startups, some in labs, some as open source projects — has also emerged in their image, designed to make applications perform and scale better, and sometimes to enable new capabilities altogether. These include technologies such as Spark, Storm and Elasticsearch.
In concert with these advances, new architectures also caught on in order to address the problems that come with trying to develop applications that can run reliably at such extreme scale.
One is the concept of microservices, which involves treating applications as a collection of services that might serve multiple applications, rather than as monolithic entities with their own dedicated components. Among other things, a service-oriented approach results in less dependency among components and the ability to scale individual services without re-architecting the entire application.
Another big architectural trend has been containerization, whether it’s done via developer-friendly means like Docker or lower-level means like Linux control groups. Containers can make it easier to plug applications into distributed services and to shift the focus from deciding where something should run; instead, containers let developers focus on what their applications need to run.
Taken as a whole, this new collection of distributed services and architectural techniques could be called the “data center application stack.” Anyone building an application that serves millions of users on multiple platforms, and can make use of the volume, variety and velocity of data today, is going to be using this collection of services or something very much like it.
In fact, these technologies are all gaining popularity fast. Many are already staples in the technology repertoires of startups trying to deliver everything from the next huge consumer app to the next Salesforce.com.
But these technologies are also making their way out of the web and into the Fortune 500, even into mid-sized businesses rarely thought of as IT innovators. They’re hearing all about what these data centers services can do — things they know they need to do at a corporate level — and they’re anxious to be a part of the excitement.
“Big data,” “real-time” and “Internet of Things” are more than just buzzwords. They’re imperatives for corporate success in many parts of the 21st century economy.
Enter the Operating System for Data Center Applications
However, the elephant in the room — which you might not hear from IT vendors, open source advocates or expert Facebook engineers — is that building out these capabilities is hard. Deploy, manage and scale Hadoop. Deploy, manage and scale Cassandra. Deploy, manage and scale Kubernetes. Rinse and repeat for every framework or service you want to use.
At some point, companies probably will want to give a little thought to actually writing the application, building the data pipeline and making sure the architecture is resilient.
Huge, engineer-rich companies such as Google and Microsoft solved (or largely solved) this problem for themselves with systems like Borg and Autopilot, respectively. The systems automatically manage resource allocation and high availability for the services and applications that run across their millions of servers. Algorithms, not developers or software architects, determine where things run and on how many machines.
Sure, they’re great systems, but they’re also proprietary. Google only recently officially acknowledged Borg’s existence by publishing a paper on it. Microsoft has done very little public discussion of Autopilot. Neither are for sale.
