
Microsoft today announced Azure Data Lake, a new data repository for big data analytics workloads, during its Build developer conference keynote.
The idea behind Data Lake is — as the name implies — to give developers a single place to store all of their structured and semi-structured data in its native format without having to worry about storage and capacity limitations on individual files.
Data Lake is compatible with the Hadoop File System, so it will play nicely with all of the standard Hadoop big data tools like Spark, Storm and Kafka, as well as services from Hortonworks, Cloudera and Microsoft’s own Azure HDInsight. Indeed, Microsoft’s corporate vice president for its data platform T.K. “Ranga” Rengarajan described this as an “important commitment to the Hadoop ecosystem” when I talked to him about today’s announcements earlier this week.
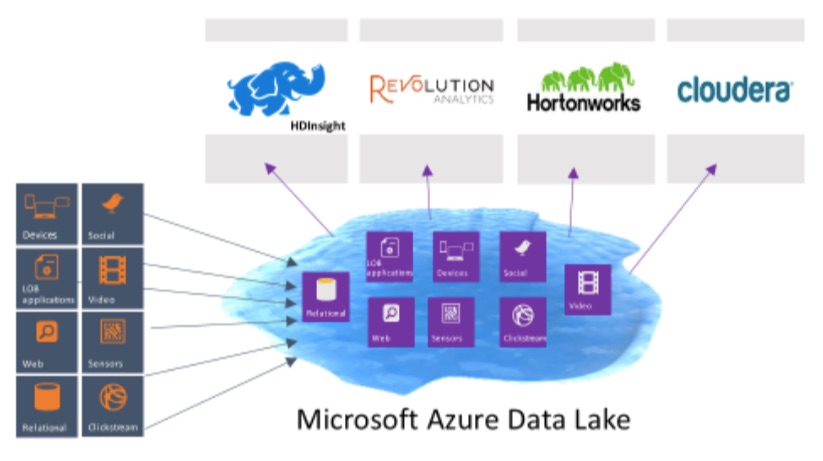
Rengarajan also stressed that Microsoft wants to allow developers to use the tools they already use, whether that’s SQL and SQL Server or Hadoop. “We want developers to be able to use the tools and frameworks they are familiar with and still be able to do all of this data processing in a friendly way,” he noted.
 The service, Rengarajan explained to me, was built on top of Azure’s hyperscale network and supports both single files that can be multiple petabytes in size, as well as high volumes of small writes and with very low latency. Because of this, the service should work well for real-time website, Internet of Things and sensor analytics, as well as for more batch-oriented big data services. Overall, though, the service is optimized for big-data analytics workloads that required developers to run massively parallel queries.
The service, Rengarajan explained to me, was built on top of Azure’s hyperscale network and supports both single files that can be multiple petabytes in size, as well as high volumes of small writes and with very low latency. Because of this, the service should work well for real-time website, Internet of Things and sensor analytics, as well as for more batch-oriented big data services. Overall, though, the service is optimized for big-data analytics workloads that required developers to run massively parallel queries.
“We’re living in the golden age of data,” Rengarajan told me. “I think of it as everyone in the world getting drunk on data. And for the first time, it’s economically feasible to get value out of the data we used to throw away.” Because it allows developers to work with a wide variety of data formats, Data Lake is Microsoft’s attempt to allow developers and data scientists to store all of this data in a central repository and then analyze it with tools they are already familiar with.
The service is now in private preview and interested developers can sign up here.
