
Earlier this week I traveled to Microsoft’s Mountain View campus to play with the company’s new Kinect sensor. While there I met with a few of the team’s engineers to discuss how they had built the new device.
Up front, two things: The new Kinect sensor is far cooler than I expected. Also, I touched an Xbox One.
The story of the Kinect device, both its first and second generations, has been a favorite Microsoft narrative for some time, as it fuses its product teams and basic research group in a way that demonstrates the potential synergy between the two.
The new Kinect sensor is a large improvement on its predecessor. Technically it has a larger field of vision, more total pixels, and a higher resolution that allows it to track the wrist of a child at 3.5 meters, Microsoft told me. I didn’t have a kid with me, so I couldn’t verify that directly.
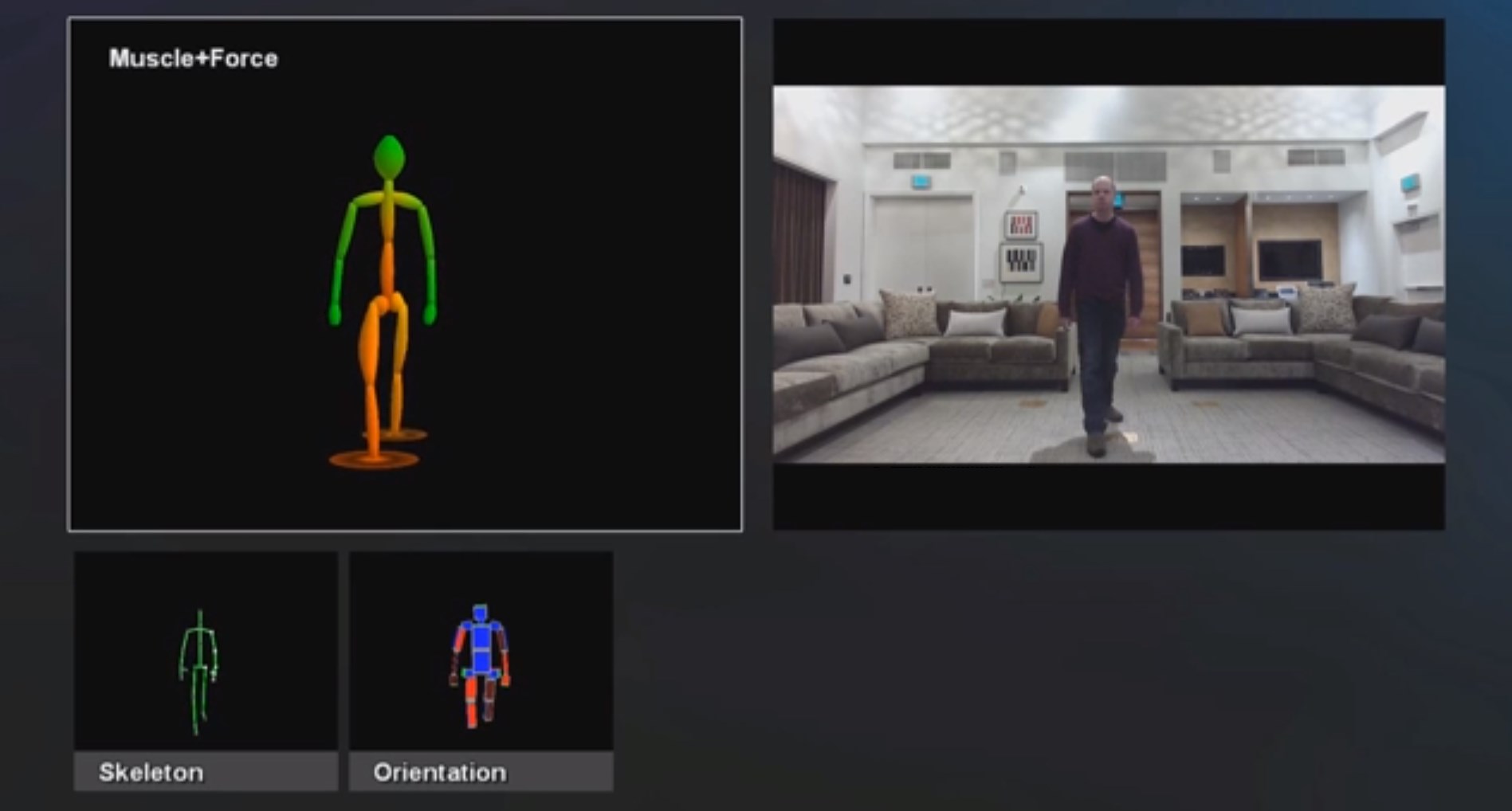
It also contains a number of new vision modes that the end user won’t see, but are useful for developers who want to track the human body more precisely and with less interference. They include a depth mode, an infrared view, and new body modeling tools to track muscle use and body part orientation.

When in its depth image mode, acting as a radar of sorts, each of the 220,000 pixels that the Kinect sensor supports records data independently. The result is a surprisingly crisp mapping of the room you are in.
The new Kinect also contains a camera setting that is light invariant, in that it works the same whether there is light in the room or not. In practice this means you can Kinect in the dark, and that light pollution – say, aiming two floodlights directly at the sensor – doesn’t impact its performance. I did get to test that directly, and it worked as promised. No, I don’t know the candlepower of the light array we used, but it was enough to suck staring into directly.

So, developers can now accept motion data from the Kinect without needing to worry about the user being properly lit, or having their data go to hell if someone turns on the overhead light, or time sets the sun. The new Kinect also supports new joints in its skeletal tracking, in case you need to better watch a user’s hands move about.
The smallest object the first Kinect could detect was 7.5 centimeters. The new Kinect, while executing a 60 percent larger field of view, can see things as small as 2.5 centimeters. And it can track up to six people, from two before.
The first Kinect device became the fastest-selling consumer device in history. Its existence helped keep the Xbox 360 relevant, even as the console aged. Microsoft is releasing a new Kinect sensor with its upcoming Xbox One. Both go on sale November 22 and will compete with Sony’s soon-to-be-released PlayStation 4.
Origins
For a one-year generational update, I feel like the new Kinect is worthy progress on its predecessor. I sat down with Microsoft’s Sunil Acharya, Travis Perry, and Eyal Krupka to track the origins of how the new hardware was designed. It’s a short story of collaboration, akin to what came together for the original Kinect device.
Most basically, Microsoft wanted to place a “time-of-flight” camera into the new Kinect. Such a device works by measuring the time it takes for light that it emits to return. Given that speed is a bit quick, and the new Kinect wanted to absorb a massive field of data in real-time, challenges cropped up.
Two of our aforementioned Softies, Eyal from Microsoft Research’s Israel group, and Travis from the mother corporation’s Architecture and Silicon Management team, collaborated on turning time-of-flight from a more academic exercise into a commercial product. Input came from what Microsoft described to me as “multiple groups” to improve the camera.
Working as a cross-team group, the time-of-flight problem was essentially solved, but it led to another set of issues: data overload and blur.
In short, with 6.5 million pixels needing processing each second, and a requirement to keep processing loads low to ensure strong Xbox One performance, the Kinect group was pretty far from out of the soup. Algorithms were then developed to reduce processor hit, ‘clean up’ edge data to prevent objects in the distance from melting into each other, and to help cut down on motion blur.
According to Eyal, executing those software tasks was only made possible by having the camera “set” earlier in the process. If the hardware hadn’t been locked, the algorithms would have learned from imperfect or incorrect data sets. You want those algorithms to learn on the final data, and not on noisy data, or beta data, he explained.
That hardware is multi-component, including an aggregation piece (Microsoft was vague, but I think it is a separate chip) that collects the sensor data from the Kinect and pools it. Microsoft declined to elaborate on where the “cleaning” process takes place. I suspect that as the firm noted on its need to keep processing cycles low for the incoming data, it at least partially takes place on the console itself.
The end result of all of the above is a multi-format data feed for the developer to use in any way they wish. Microsoft spends heavily on the more than 1,000 developers and Ph.D.s that it employs at Microsoft Research who are free to pursue long-term research that isn’t connected to current products. But it does like to share when those lengthy investments lead to knowledge that it applies to commercial devices, such as the Kinect.
What to take from this? Essentially that even before the re-org, Microsoft had at least some functional intra-party collaboration in place. And, that a neat device came out of it.
The next challenge for the team? Make it smaller.