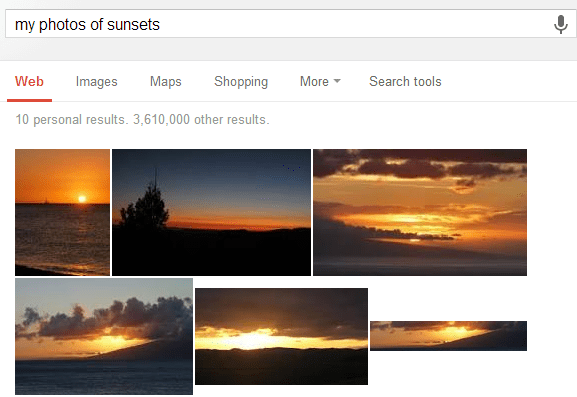
During its I/O developer conference, Google quietly introduced a massively improved version of its photo search feature in Google+, which now uses advanced computer vision to let you search your personal photos. The company didn’t make a big deal about this tool, but it works extremely well. Today, Google is opening up a bit more about how it got to develop this new photo search experience in just about six months.
The system, Google’s Chuck Rosenberg writes, is essentially the next version of the general Image Search over web images Google has offered for about twelve years now. That tool, however, mostly relied on image filenames and text from the web to classify these images. That’s not really possible with personal photos, which often have no context beyond some basic EXIF metadata. “The average toddler [was] better at understanding what [was] in a photo than the world’s most powerful computers running state of the art algorithms,” Rosenberg writes about this approach.
Last October, however, Professor Geoffrey Hinton’s group at the university of Toronto developed a system based on deep learning and convolutional neural networks that easily won the ImageNet computer vision competition with a huge margin. This changed things and a group at Google built and trained a system that used a similar approach to start working on this problem and recognized that this would help it make photo searching more precise and easier.
To make this possible, Google acquired DNNresearch in March, the startup that was spun out of the original research by Hinton’s group. Until now, it wasn’t clear what this team was working on at Google, but now we know the answer. When Google acquired the company, which was founded by Hinton and two of his graduate students, Alex Krizhevsky and Ilya Sutskever, we weren’t sure if Google was doing so for Hinton’s work on speech recognition, language processing or image recognition.
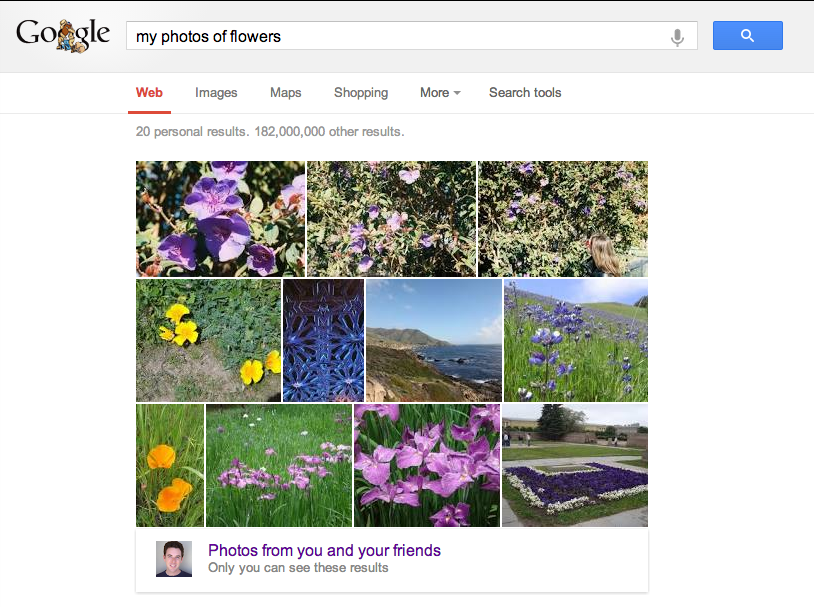
As Rosenberg notes, the company tool this “took cutting edge research straight out of an academic research lab and launched it, in just a little over six months.”
Photo search today uses about 1100 classes, based on the Freebase entities that form the basis of Knowledge Graph. Today’s post delves a little bit deeper into how the system works and handles different kinds of images. It’s worth noting that Google says the system worked better than it expected, especially for specific subclasses like “hibiscus” or “dahlia” (I wouldn’t know the difference between the two…).
Rosenberg notes that computer vision isn’t solved “by a long shot,” but we are getting close to getting computers “to see the world as well as people do.”