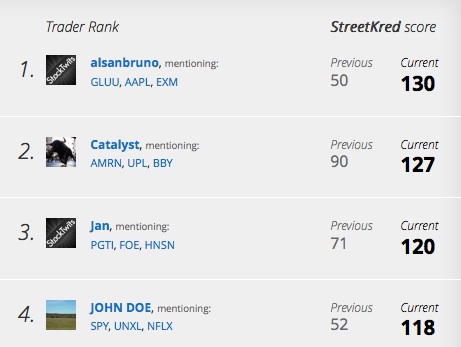
So there’s this startup called SmogFarm, which does big-data sentiment analysis, “pulse of the planet” stuff. I spotted them last year, and now they’ve got an actual product with an actual business model up and running in private beta: KredStreet, “The Social Stock Trader Rankings,” which performs sentiment analysis on StockTwits data and a sampling of the Twitter firehose to determine traders’ overall bullish/bearish feeling. They also compare reality against past sentiment to score and rank traders based on their accuracy, which is more interesting.
It’s a first iteration, but it looks pretty nifty, and I like the idea of a ranking system wherein unknowns can leave high-profile loudmouths in their dust by virtue of simply being right more often. Even if I feel slightly uneasy when I imagine such a system being applied to, say, tech bloggers. Actually being held accountable for what I’ve written in the past? Doesn’t that just seem terribly wrong?
And of course it’s early days yet for companies like SmogFarm/KredStreet, and sentiment analysis, and natural language processing (such as that which powered Summly), and Palantir-style data mining. Just imagine what they’ll be able to do in five years. And when they turn all that big-iron, big-data searchlight power on, say, Facebook timelines — what won’t they be able to determine?
A few years ago the EFF discovered that something as simple as your browser settings make you a lot less anonymous online than you might believe. Last week a study found that “human mobility traces are highly unique,” and when polling allegedly anonymous cell-phone location data, “four spatio-temporal points are enough to uniquely identify 95% of the individuals.” Good software can mine a lot of meaning out of apparently sparse and empty data.
So just imagine what happens when next-generation language- and image-processing software, and then the generation after that, and the generation after that, is unleashed on your Facebook timeline. It seems very plausible that all those innocuous things you say, and how you say them, and the pictures you post, and the games you play, will subtly and invisibly add up to a terrifyingly accurate portrait of you, including any and/or all of the things about yourself that you never actually wanted to make public.
What’s worse is that it will be ridiculously easy. Would-be employers won’t have to scroll through your Facebook timeline themselves, they’ll just need to point their profiling software in your direction and 30 seconds later read its high-confidence predictions of your work habits, neuroses, personal failures, emotional instabilities, attitude towards authorities, and sexual proclivities, all expertly extrapolated from the tapestry of subtle-to-invisible nuances accumulated from all of your photos, comments, Likes, upvotes, etc.; all individually meaningless, but collectively highly illuminating. Individual profiling is a huge business just waiting to be tapped by ethically challenged startups.
(This could be mitigated somewhat if you were to keep all your activity friends-only, of course; but even then, every app or distant acquaintance you’re connected to will be able to learn more about you than you ever intended. And it’s easy to envision employers requesting that you connect to them on Facebook as part of the job-application process, and filtering out those who refuse…)
I can imagine what that kind of profiling software would have said about me, early in my career: Hopeless bibliophile. Afflicted with incurable wanderlust. Doesn’t like being told what to do. Extremely chancy hire: likely to quit any job after six months to travel or try to write the Great Canadian Novel. Which, er, would have been one thousand per cent true; but obviously I didn’t want my potential employers back then to know about it.
Doesn’t matter to me now, of course, now that I’ve mellowed out some and I’m pretty well-established. But when people who are still struggling discover that everything they do online says far more about themselves than they know, and will be ceaselessly stored, sifted, mined and measured…they’ll inevitably become a whole lot less forthright than they are today.
Most people already know not to publicize individual things that reflect badly on them; once they realize that the totality of what they post can have serious repercussions, too, they’ll clam up. In the end all public online activity will essentially become an endless ongoing job interview. Doesn’t that sound great?
You would think all this big-data artillery would be good news for Facebook, so that they can target their ads more effectively. But once everything you share is being watched, filtered, and graded by remorseless, relentless profiling software, you’ll inevitably begin to share far less. Sure, you can try to use pseudonyms…but screw up just once and they’ll be tied to your real identity forever.
“Zuckerberg’s Law” states that every year the amount of information shared by Internet users doubles. But KredStreet and the like are only the very beginning of what can be done with this kind of data analysis. It’s hard to imagine Zuckerberg’s Law marching on once people realize that everything they do online accumulates into data that reveals far more about them than they know, which can and will be used against them. Instead I can see Facebook slowly turning into a ghost town where everyone is always on their very best fake behavior.