This guest post was written by Kovas Boguta, Head of Analytics at Weebly. In 2009, Kovas wrote a guest post about visualizing real-time social structures.
A decade ago, the open-source LAMP (Linux, Apache, MySQL, PHP/Python) stack began to transform web startup economics. As new open-source webservers, databases, and web-friendly programming languages liberated developers from proprietary software and big iron hardware, startup costs plummeted. This lowered the barrier to entry, changed the startup funding game, and led to the emergence of the current Angel/Seed funding ecosystem. In addition, of course, to enabling a generation of webapps we all use everyday.
This same process is now unfolding in the Big Data space, with an open-source ecosystem centered around Hadoop displacing the expensive, proprietary solutions. Startups are creating more intelligent businesses and more intelligent products as a result. And perhaps even more importantly, this technological movement has the potential to blur the sharp line between traditional business and traditional web startups, dramatically expanding the playing field for innovation.
PROBLEM, MEET SOLUTION
Even a modestly successful startup has a user base comparable in population to nation-states. The resultant mass of user data creates problems and opportunities. Problems because understanding the value of every user and transaction becomes more complex. Opportunities because the collective intelligence of the population can be leveraged into better user experiences.
Until just a year or two ago, analyzing this scale of data required the same kind of enterprise solutions that LAMP was created to avoid. Multiyear, multimillion dollar deals with the likes of IBM, Oracle, and Teradata. Of course, almost no startup can afford that kind of expense. Furthermore, the closed-source technological pedigree of these solutions makes them incompatible with startup engineering knowledge and culture.
Enter Hadoop. Hadoop solves these data processing problems in a way that is both startup-compatible, and technologically superior. As an open-source project developed by and for engineers, it’s very practical and squarely in the mainstream of startup engineering practice. And its architecture of map-reducing across of a cluster of commodity nodes is more flexible and cost effective than traditional data warehouses.
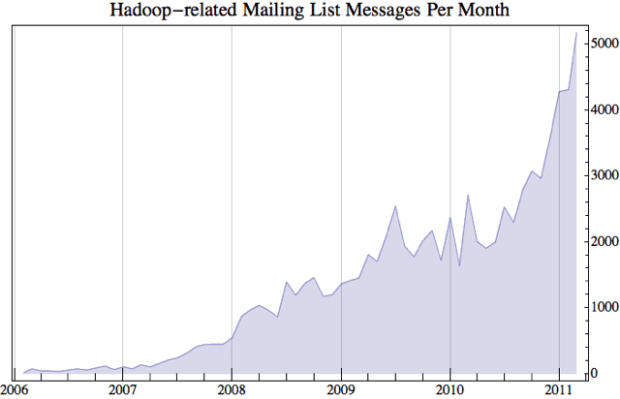
Given the pent-up demand, it’s no surprise then that Hadoop is blowing up. To see how an open-source project is doing, the first thing you do is look at the developer mailing list traffic. If you gather all the Hadoop-related mailing lists and plot the number of messages, you get the classic hockey stick growth curve:
In today’s world, it’s not much of a stretch to say that the future of technology is shaped by developer adoption. As more engineers and more startups adopt Hadoop, its capabilities are becoming a default assumption when designing the products and businesses of the future.
HADOOP IN TODAY’S STARTUPS
At the high-level, there are 3 areas where Hadoop is finding application in today’s startups: 1) Analysis of customer behavior, 2) Powering new user-facing features, and 3) Enabling entire new lines of business that were previously out of reach.
Eventbrite is an example where Hadoop is powering new user-facing features. The rapidly-growing events service lets organizers manage and promote their events, and helps users find relevant events to attend. To help grow the company faster, their data services team is using Hadoop to feed intelligence in, under the hood, into various parts of the product. For example, a recommendation system helps users find relevant events, and an automated classification system helps reduce user friction for creating new events.
At Weebly, we’ve deployed Hadoop to get measures of customer value — which users are going to bring in the most revenue, and how can we most effectively target them? This is a fairly complex calculation, involving many factors and data sources. With Hadoop, we can say “Let’s just compute it.”
A final category of usage is startups built from the ground up on Hadoop. Backtype, a marketing intelligence platform, is perhaps the archetype of the new species of startup made possible by Hadoop. The team of three engineers run its operation, consisting of over 25 terabytes of data and 60 servers for data processing, serving the dashboard UI, and providing data APIs to other companies. The industry incumbents have a huge investment in teetering older architectures, with little chance of matching Backtype’s iteration cycle.
HADOOP: A MOVEMENT, NOT JUST A TECHNOLOGY
Despite Hadoop’s utility, the predictable backlash has claimed it is overhyped, pointing to shortcomings like ease of use, ability to process realtime data, limitations of map-reduce for social graph data, etc. But this is like criticizing LAMP for PHP’s ugliness before Ruby on Rails took the stage, or MySQL’s scalability issues before Memcached sidestepped them.
The key to understanding Hadoop’s significance is that it’s not just a specific piece of technology, but a movement of developers trying to collectively solve the Big Data problems of their organizations. As the Hadoop growth curves illustrate, the technological foundation for a data-oriented open-source ecosystem has been laid, and a family of related technology is starting to emerge. Exactly in the same way Rails, Memcached and arguably even the Cloud emerged from the LAMP movement.
Already, HBase is rapidly gaining credibility as a realtime processing system, while efforts like Spark point to generalized architectures that can handle tasks like network analysis. And on the usability front, Cloudera has done much to simplify installation and administration, though more opportunities remain.
What is most remarkable is how the startup world is collectively creating this ecosystem: Yahoo, Facebook, Twitter, LinkedIn, and a whole slew of earlier-stage companies are very actively contributing to the tool chain. This illustrates a new thesis or collective wisdom emerging from the Valley: If a technology is not your core value-add, it should be open-sourced because then others can improve it, and potential future employees can learn it. This rising tide has lifted all boats, and is just getting started.
KEYS TO THE ENTERPRISE KINGDOM
There is an iron curtain in today’s tech world, separating startupland from the enterprise. Two technological ecosystems, engineering practices, and ultimately assumptions about what kinds of businesses are possible. But with Hadoop, startups are now creating substantial innovations on what is essentially business data, creating a common platform highly relevant to both worlds.
Hadoop is the ultimate trojan horse in enterprise IT. It strikes at the heart of business — the data — in a way that adds value immediately, while setting the stage for viral growth in the future, connecting the two ecosystems and the technological and cultural levels. The potential end result: a greatly expanded playing field for future startups, and cheaper, more flexible, and more relevant
solutions for the enterprise.
From the beginnings of computing, enterprise IT has ultimately been about the data. But the Kafka-esque proliferation of proprietary solutions and solutions to the solutions has made innovating on business data nearly impossible. You might have a better mousetrap, but you’re toast if it doesn’t “integrate”.
So who is going to integrate Hadoop in the enterprise? Amazingly, it’s the vendors themselves. Partially because of the hype, and partially because of real advantages in areas like unstructured data processing, the vendors are falling over themselves getting Hadoop-branded solutions to market. See for example EMC’s line of Hadoop data appliances, and IBM’s Hadoopified Big Insights platform. A Hadoop arm’s race appears to be well underway.
And now the key point: Hadoop adoption in the enterprise provides a hook for the rest of the open-source ecosystem, from data analysis, to web and mobile technologies, to the engineering talent pool. With a standardized Hadoop integration point, one can just download the Yahoo Latent Dirichlet Allocation code from Github and start datamining customer support emails. Or customize the Hive frontend for business analysts. Or use HBase to coordinate realtime dataflow between divisions. Or connect the data backend to any number of web or mobile applications. This massive catalog of open source software and hugely talented pool of developers can be “integrated with” via Hadoop.
In short, Hadoop has the potential to make the enterprise compatible with the entire rest of the open-source and startup world, by starting with the data and then extending out to the rest of the family tree, from the web, to the cloud, to mobile, to best practices for software engineering management. For once you can systematically manipulate the data, you have the keys to the kingdom.
