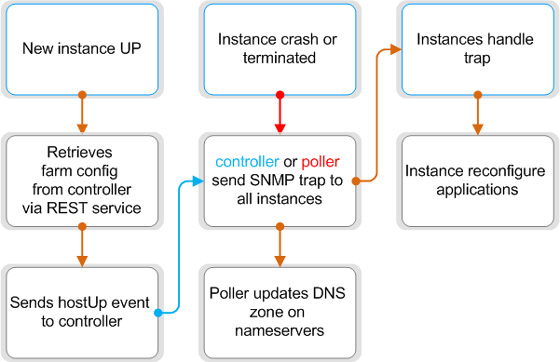
Scalr is a recently open-sourced framework for managing the massive serving power of Amazon’s Elastic Computing Cloud (EC2) service. While web services have been using EC2 for increased capacity since Fall 2006, it has never been fully “elastic” (scaling requires adding and configuring more machines when the situation arises). What Scalr promises is compelling: a “redundant, self-curing, and self-scaling” network, or a nearly self-sustainable site that could do normal traffic in the morning, and then get Buzz’d in the afternoon.
The Scalr framework is a series of server images, known dully in Amazon-land as Amazon Machine Images (AMI), for each of the basic website needs: an app server, a load balancer, and a database server. These AMIs come pre-built with a management suite that monitors the load and operating status of the various servers on the cloud. Scalr can increase / decrease capacity as demand fluctuates, as well as detecting and rebuilding improperly functioning instances. Scalr is also smart enough to know what type of scaling is necessary, but how well it will scale is still a fair question.
Those behind Scalr believe open-sourcing their pet project will help disrupt the established, for-pay players in the AWS management game, RightScale and WeoCeo. Intridea, a Ruby on Rails development firm, originally developed Scalr for MediaPlug, a yet-to-launch “white label YouTube” with potentially huge (and variable) media transcoding needs. Scalr was recently featured on Amazon Web Service’s blog.
I’d argue that Scalr makes Amazon EC2 significantly more interesting from a developer’s standpoint. EC2 is still largely used for batch-style, asynchronous jobs such as crunching large statistics or encoding video (although increasingly more are using it for their full web server setup). Amazon for their part is delivering on the ridiculously hard cloud features, last week announcing that their EC2 instances can have static IPs and can be chosen from certain data centers (should really improve the latency). But for now, monitoring and scaling an EC2 cluster is a real chore for AWS developers, so it’s good to see some abstraction.