Radar Networks, the not-so-secret stealth startup, is finally unveiling its site, dubbed Twine. Twine is targeted straight at groupware and knowledge-management apps that have mostly been confined to enterprise installations, and opening that up to a broader base of consumers. The startup has raised $5 million from Paul Allen, Peter Rip, Ron Conway in April, 2006, and has done work for DARPA.
Radar Networks, the not-so-secret stealth startup, is finally unveiling its site, dubbed Twine. Twine is targeted straight at groupware and knowledge-management apps that have mostly been confined to enterprise installations, and opening that up to a broader base of consumers. The startup has raised $5 million from Paul Allen, Peter Rip, Ron Conway in April, 2006, and has done work for DARPA.
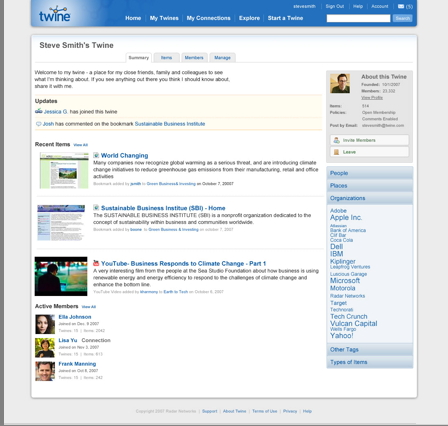
CEO Nova Spivack took me through a demo. On the surface, Twine is a place to organize information you find or create on the Web—bookmarks, notes, videos, photos,contacts, tasks. (A Web browser plug-in makes it easy to save stuff to your Twine wherever you may find it on the Web). 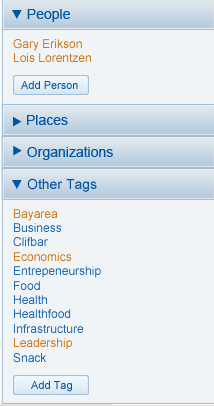 You can also share that information with a private group or publicly. Once you ingest in all the information you want to organize, Twine applies a semantic analysis to it that creates tags for each document or video or photo. The tags match up to concepts that Twine’s algorithms associate with each piece of content, regardless of whether that concept is specifically mentioned in the Web page or other content being tagged. For example, you might bookmark this post and Twine would create tags for all the people mentioned in it (Nova Spivack, Paul Allen, Peter Rip, and Ron Conway). It would also create tags for the organizations related to the post, such as Radar Networks and DARPA, but also Paul Allen’s venture firm Vulcan Capital—even if Vulcan was never mentioned in the post.
You can also share that information with a private group or publicly. Once you ingest in all the information you want to organize, Twine applies a semantic analysis to it that creates tags for each document or video or photo. The tags match up to concepts that Twine’s algorithms associate with each piece of content, regardless of whether that concept is specifically mentioned in the Web page or other content being tagged. For example, you might bookmark this post and Twine would create tags for all the people mentioned in it (Nova Spivack, Paul Allen, Peter Rip, and Ron Conway). It would also create tags for the organizations related to the post, such as Radar Networks and DARPA, but also Paul Allen’s venture firm Vulcan Capital—even if Vulcan was never mentioned in the post.
What Twine does is automatically generate smart tags and connect them together. There is also a social element. If you share a Twine with others, each piece of content that someone brings into that online space is associated with that person. So when you do a search, the results that come back are influenced not just by the tags, but also by who put the information into the Twine in the first place. “It’s the wisdom of crowds plus the wisdom of computers working together,” says Spivack. The more closely related that person is to you, the higher the relevance. At the same time, Twine is creating a very detailed profile of your interests which it hopes to run highly targeted ads against.
Twine is putting structure onto all of this unstructured data that is out there by analyzing it and adding tags to it that are connected together. The network of links between these tags is something that Spivack calls the “semantic graph,” which includes the “social graph” that is made up only of those tags categorized as people. Bu the semantic graph is bigger than that, comprising other tags such as organizations, places, and other categories.
Rather than create a semantic index of the entire Web, which would be a huge undertaking, Spivack is starting with just those parts of the Web people feel are important enough to save in their collections. Then he applies natural language processing and semantic indexing to just that data. “If you just sucked in the whole Web,” he says, “you would get stuff people didn’t want. Here we are looking at who thought it was important and why.” It’s also cheaper to do it this way, since it’s a more limited set of data that needs to be run through Twine’s semantic engine.
Everything in Twine will become widgetizable and exportable elsewhere. There will also be a full set of APIs. All the data will be able to be taken in and out. Other search engines will be able to index anything in a public Twine, along with the smart tags that have been appended to the information there. “When you put stuff into Twine,” says Spivack, “Twine enriches it, but you can take it out.” Of course, all of those enriched tags will point right back to Twine. “We’re the only place that can even see the connections between things,” says Spivack. Well, not quite yet. People have to start using Twine first.