
The internet was a revolution because it reorganized a large part of the economy and society around the network structure, becoming a fantastic medium for commerce, finance, power and culture. It also definitely changed our perception of time and space. We now live in a globalized and connected world where information flows at the speed of light.
What about data?
We all know that data is a big thing. What my colleagues and I wanted to do, however, was go beyond the current doxa to try to understand why and how big it actually will be. Above all, we wanted to base our study on a bottom-up approach. To do this, we manually analyzed more than 3,000 funding rounds from tech companies in the EU over the past two years, looking for data on data startups. We had a lot of questions to answer; who they are, what they do, how large the investments in this sector are, etc.
Looking at the physical activities of each startup, we developed a framework based on objective criteria, which allowed us to define what a data startup is, using it for classification purposes. We called this framework the “data chain,” illustrating the main characteristics of data startups and the fact that data companies can be involved both in a physical layer (storage and processing) and a digital layer (non-trivial data collection, interpretation and actionable data production).
Our definition of the data chain came about with all the value brought by data at each of these stages. It directly reflects what startups from the data ecosystem have in common. Each of the 130 startups we classed as being a data startup for the purpose of this study satisfy at least one condition of this definition.
![]()
Based on this definition, we measured that €1.2 billion was invested in these 130 European “data champions” in 2014 and 2015.
![]()
In terms of geographic distribution, it is the U.K., France and Germany that lead the game in regards to both the total amounts invested (61 percent) and the number of startups funded (65 percent) over this period.
![]()
![]()
![]()
The data startups identified can be divided into 26 distinct business sectors:
Number of funded EU data startups in 2014 and 2015 per sector
What struck us first was the fact that the traditional sector was also concerned by the “datafication” of the economy. Health, Automotive, Energy, Agriculture and Environmental data is already being used almost everywhere. Non-digital economics are being “data-fied,” as well. Regarding digital sectors, we see there is a significant portion of startups trying to improve the way a company can understand and address its customers or potential prospects.
Two examples of amazing data startups
AdasWorks is an artificial intelligence company for self-driving cars based in Hungary.

Its six cameras transform real-time views of the road into data (corresponding to “non-trivial data collection” in our data chain). Its algorithm interprets this data, understanding the road and its context (interpretation) and produces concrete outputs like acceleration/deceleration or rotation angle turned into action (actionable data). In the case of self-driving cars, data means a massive future disruption of the automotive industry and improved road safety.
Enevo applies data to the environment and waste collection.
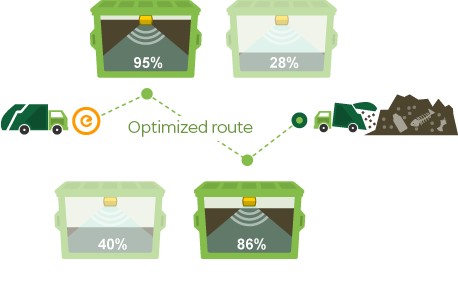
This startup based in Finland analyzes sensor logs in real time, being able to tell how full any city’s trash is and delivering optimized collection routes (interpretation and actionable data). Thanks to Enevo, dustmen can now focus and limit their collection to trash that needs collecting and thus invoices citizens based on their real waste production. Data in this case means fewer trucks, journeys, gasoline and CO2 — and more satisfied citizens — whilst at the same time providing a better pricing for cities.
Why is the data paradigm so revolutionary?
Looking back at history, and especially the history of science, we have several examples of technological revolutions. Some deal with interaction between people: writing, money, printing or the internet. Others are about domesticating nature, like fire, steam machine or electricity.
Very few are about perception; the way we look at the world. Among the most reputed inventions (several hundred), we found that very few of them were really able to disrupt human perception: the telescope in 1586, the microscope in 1650 and modern medical imagery, which started in the 19th century with the discovery of the X-ray.

Galileo showing the satellites of Jupiter to Venetian senators
The telescope has definitely changed our perception of the universe, leading to the Copernican Revolution, when science and reason triumphed over dogma. The microscope has changed our perception of the infinitely small, giving birth to disciplines like microbiology or immunology. Before 1850, doctors didn’t believe in microbes. Can you imagine medicine without microbiology? And modern imagery considerably improved our understanding of the human body.
These were tremendously huge revolutions, because they changed the way we look at the world, they were able to impact and largely disrupt our perception. Changing perception transforms everything and allows new horizons.
The collection and interpretation of huge amounts of data through diverse kinds of measures and statistics/AI technics means that data is a disruption bringing a new perception paradigm. It is like the microscope, but lets us understand a (larger and larger) part of the physical world through its projection on the data space. Wherever we have sensors, data or any ability to translate something into a digital signal, the data magic can occur and we are able to crunch data for a better understanding.
But there’s more: The data revolution means not only a new kind of perception for humans, but also… the start of perception by machines.
A new kind of perception for us and the start of perception by machines
Remember the “data chain” we introduced at the beginning:
- Sensors allow machines to literally feel the real world
- The cloud enables them to share all together their own experience
- AI technics unlocked machine learning
- APIs turns machine decision-making into concrete action
Cloudified AI means there is a feedback loop in the data chain. Machines are not only able to sense the real world, identify patterns, decide and take action, but they are also able to learn from their collective experience.
![]()
When I’m driving my car on a new road, I can learn about it: some of its specificities or dangers, like a hazardous turn. It will probably be useful to me the next time I take this road. But I can’t share this knowledge with anybody else, and this information stays with me. However, when you’re being driven by a self-driving car on a new road, the car will learn about it, upload the data in the cloud and thus share this knowledge with other self-driving cars. In a short time, every road will then be known by your car, even though you’ve never been there. Shared experience and learning by machines will be a very powerful tool in the future.
Indeed, cloud interaction between machines, through a database, enables a very special kind of synergy, well-known by entomologists and AI-specialized computer scientists as “stigmergy.” Look at ants: They are very basic animals, but interacting with each other using pheromone dispatched on their path makes the colony have a seemingly intelligent behavior. Stigmergies can produce complex processes without the need for any control or direct communication between agents. Data is like pheromones for machines: Data is network. It will probably account for unexpected and interesting properties in the data ecosystem.
The potential of data
Data, as a connection between cloudified artificial intelligence and the physical world, is a new and normalized access point for tech to address the world’s challenges, allowing tech people to operate, from the data space, on physical world issues, such as:
- Self-driving cars, which could help to solve the 1.3 million deaths on the road each year (I’m assuming that computers will never get drunk).
- Precision agriculture, which uses sensors directly in the ground to monitor and address the soil’s needs, and will help to improve crop yields with fewer pesticides/fertilizers. This is a perfect example of how deep data is becoming integrated into the real world, directly plugged into nature. As there are 800 million undernourished people in the world, with at the same time a growing global population, this is a key challenge.
- Smart grids, which allow electricity producers to adapt electricity consumption to their production capacities instead of adapting production to consumer needs, and could thus help to reduce by 18 percent CO2 emissions of electricity production in the U.S., according to the U.S. Department of Energy.

© Alf Ribeiro / Shutterstock
As data is a perception game-changer, it has already started to disrupt many sectors. Its potential is as big as the problems that data can address are numerous, diverse and impacting. Archimedes said “Give me a place to stand and with a lever I will move the whole world.” Enabling the self-organization of intelligent machine networks, operating from the data space on the physical world, data is more than simple information; it is a new medium between humans, machines and nature allowing us to leverage our new digital abilities to go further.