It’s 3:30 am in the featureless Singularity University meeting room I’m peering into via Skype and I’ve just asked Marita Cheng to take a photo of the buttons on her co-founder, Alberto Rizzoli’s, shirt. It’s definitely one of the stranger requests I’ve made of tech founders, at any time of day, but the pair don’t bat an eyelid — and in half a minute a robotic voice pipes up from Cheng’s iPhone informing us that the shirt Rizzoli is wearing is called a Henley shirt.
That’s not all. The voice specifies that a brunette male is wearing a white Henley shirt. As tech demos go it’s pretty smooth. And I’ve learnt some bonus sartorial nomenclature. Not bad for a Monday morning (UK time). It may be the middle of the night in Silicon Valley but you’d hardly know it; Cheng and Rizzoli’s enthusiasm for what they’re building is demonstrably eclipsing their need for sleep. That and a looming demo day for which they’re busy prepping slides.
Singularity University’s mission is all about applying “exponential technologies”, such as artificial intelligence and machine learning, to push boundaries to solve key challenges for humanity — albeit the margins of sleep are evidently the first to get rolled back by the intensity of the program’s focus. Hence some current students dubbing it ‘sleepless university’.
“Our dorms are 10 meters away from the classroom. It’s like a Singularity University bubble,” says Cheng, who’s from Australia and has a background in robotics coupled with tech education startups.
“There’s no privacy,” adds Rizzoli, with a laugh. He moved over from London to attend the program. Prior to SU he founded a tech education 3D printing startup, among other entrepreneurial activity. “Everything is free. Everything is sponsored by Google. So we have the most relaxed lifestyle possible in our 4.30am work days,” he deadpans.
The pair are one of 27 teams formed on the SU’s 10-week Graduate Studies Program which will be pitching at demo day this Tuesday. Five teams will then be selected to present at the program’s closing ceremony on Thursday. All direct entry applicants to the program are being funded by Google this year and next.
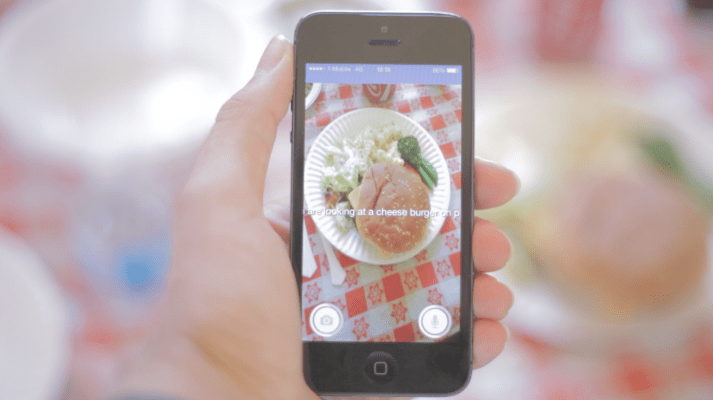
So what are these two midnight-oil-burning entrepreneurs building? The iOS app they are demoing to me is called Aipoly — it’s due to land on the App Store in about a week (they’re in the midst of submitting it to the store when I Skype in). It’s an intelligent assistant app that uses computer vision and machine learning technologies to recognize what’s going on in photos.
Initially they are targeting it at blind and visually impaired people, to help them navigate or identify objects by taking a photo on their iPhone and getting an audio description in return — all without having to rely on asking anyone else to help them. The team has focused on developing on iOS first because of the platform’s existing accessibility features which make the device popular with their target users.
It’s cautious. Before it says that someone is angry it has a very low threshold for saying that a person is in fact angry.
“We thought what if we created an algorithm that would paint a scene in front of [the user]. I would usually guide [a family friend who is blind] through a new area,” says Rizzoli. “And describe to them there’s a statue to the right, there’s a hedge and a fence to the left and a pair of trees in front of us. And I thought what if machine vision could do that? What if computer vision could do that automatically without these people having to rely on other humans for their sense of independence, and their sense of wonder and exploration?”
Users take a photo within the app and it’s uploaded to the cloud for processing. Once the machine vision system has identified what it’s looking at in the photo it returns the answer in text and speech form. For the initial MVP the team is not using their own algorithms — but does plan to develop their own and train them with specific data-sets for their target users, says Cheng.
“It’s a very simple application. It takes a picture and it uploads it to a server where it uses a system of what’s called convolutional neural networks to look through the picture. Essentially it… subdivides it into different points of interest… and matches each one of them to a particular object,” explains Rizzoli, discussing the core tech.
The system can discover multiple objects in a scene, such as different items on a table, and also understand relationships between objects in the image — such as being able to specify that a person is riding a bike, for instance.
“If we were to take a picture of a person riding a bicycle an algorithm from 2010, state of the art, would probably spew out the keywords ‘person’ and ‘bicycle’ but today they can actually find relationships between objects. So ‘person’, ‘riding’, ‘bicycle’. So pretty advanced concepts for a computer to understand,” he adds. “This is why this technology is becoming very exciting for the accessibility market.”
The whole process can take as little as five seconds on a fast Wi-Fi network to around 20 seconds where network speeds are slower or the scene being analyzed requires more ‘algorithmic thought’. The technology has been trained with around 300,000 images at this stage, says Cheng. The plan is to continue building this out, with a specific focus on imagery that might be useful for blind and visually impaired users — such as street signs or specific items they may need to use or locate like white canes, braille readers or even their guide dog (assuming the dog is sleeping too deeply to hear them call).
“We went to a picnic on Saturday with the Silicon Valley Council For The Blind and we took pictures of everyone’s white canes in lots of different positions, and we will upload all of those images to our algorithm such that if a blind person has dropped their white cane somewhere and they’re not quite sure where they can get their phone out, take a picture in the vicinity where they think their white cane is and have the app identify that there is a white cane that they’re looking at and that’s where they should search around,” she adds.
At the start of this year a Danish app called Be My Eyes grabbed attention with a similar concept — albeit entirely powered by human eyes. So that app connects blind and visually impaired users who have a need to identify something specific — such as a label on a can of food — with sighted users willing to lend their eyes to the task at hand so they can tell them what they are looking at in real-time.
Aipoly is seeking to fix a similar problem — so from help with navigation, to identifying photos in a photo album or plates of food, clothes or colors — but applying technology to the task. Both approaches are valid and useful. And while it might seem like it feels nicer to ask a fellow human for help (vs asking a machine), for the person in need of help to see it may actually feel easier and nicer to ask a machine — being as it allows them to be less dependent on others, argues Cheng.
Using algorithms to automate what amounts to dynamic audio description has been made possible thanks to relatively recent breakthroughs in the field, coming out of joint research between Stanford and Google in 2012, according to Rizzoli. “That improved the precision of the algorithm by more than twice by improving the way the convolution is made — essentially the subdivision of pictures.”
“These breakthroughs have been pretty consistent in the past 10 years so we can expect this kind of technology to be even quicker and more precise in the coming years,” he adds.
In terms of limitations, the machine vision tech obviously has some — it may not always correctly distinguish between genders, for instance. And while it can recognize certain very strong and distinct facial expressions — such as a person smiling broadly or someone looking very angry — it’s not yet very sensitive (although improving emotional recognition is an area the team hopes to work on).
“It’s cautious,” says Rizzoli of the algorithm. “Before it says that someone is angry it has a very low threshold for saying that a person is in fact angry. It does the same for recognizing genders.
“It will think very hard before calling someone a man when it’s not too sure because it can be a bit impolite if that person is actually female. But it will sometimes do the opposite for a man and identify them as a woman. That’s happened in a few occasions.”
The tech also obviously fares less well if the photo quality isn’t great — so if the photo snapped is a bit blurry. For instance a close-up shot of the label of an empty plastic bottle of orange juice snapped by Rizzoli during our Skype call is christened a ‘naked glass jar’ by the algorithm, with its machine vision eyes lifting the brand name ‘Naked’ and seeing glass, rather than the more prosaic plastic. So there’s clearly scope for confusion. (But also, dare I say it, a little serendipitous poetry.)
Latency is another clear limitation. The cloud-processing time inevitably constrains the utility — and that’s going to remain a barrier for the foreseeable future. “When you ask what is the weak point, I would say it is the time it takes to get that information back,” concedes Cheng.
Real-time processing is not possible as this stage, adds Rizzoli, although they are working on refining the per processing time (he’s hopeful this can generally be reduced to five to six seconds per shot).
Nor is it possible to do the image processing locally, on a mobile device. It would just take too long to do that. That’s something for the even farther flung future.
“It’s not real-time. It’s not something you can strap to your ear with a camera and it tells you exactly what’s in front of you — yet. But there is no reason why we should think that it won’t be in the upcoming years,” says Rizzoli. “It would be great to do it on a local device but it would take too long. It would take something like 25 minutes to half an hour on an iPhone to process.”
Relying on cloud-processing also has the benefit of feeding more data back to the algorithm — allowing everyone’s experience and app inputs to benefit from collective processing, adds Cheng.

While Aipoly has an initial target of visually impaired users, the team sees wider applications for the technology — discussing more general use-cases for a machine vision app that can identify real-world objects, whether it’s for satiating kids’ curiosity about unfamiliar objects they encounter in the world around them, or offering an updated field guide experience for specialist interest communities, such as bird watchers.
Beyond that, their perspective on what the tech could do zooms out even further. Rizzoli talks about how it could be used to power a searchable layer for finding real world objects — and as a navigation aid for robots, as well as humans.
“We are experimenting with building a layer of searchable context on top of the physical world, based on the objects found by this certain algorithm,” he says. “This is still something we are trying to build conceptually. But the idea is what if not just people but robots and robotics and machines could navigate through the real world and recognize objects and the relationship with distances, with colour, within the interiors of a building, or even the exteriors we can have with Street View. And log them with keywords, layer them on co-ordinates, so you could potentially search for items within your home or landmarks and shops within places like airports without having to manually map them on a GPS map.”
In the meanwhile, the initial business — and it is a business they’re building — will be focused on their core market of blind and visually impaired users, and will likely be a subscription offering for using the app, says Cheng.
“Things that blind people have told us they find difficult to find include rest rooms, and they also said it’s difficult to navigate in airports, train stations and stadiums,” she adds. “Currently all airports are different, laid out differently, it’s hard to know your way around. But if the interior of buildings was mapped and stored somewhere then a blind person could have their phone with them, hold it up while they walked round an airport, it could take pictures of their surroundings as they walked, that could be matched with this database of interior images that have been created and the app could tell the blind person walk forward for another 20 feet and then turn right. And that’s something that blind people have said that they would really appreciate.”
The idea for the Aipoly was sparked after Cheng went to Google.org for a meeting to discuss some of her other projects, and ended up talking about the forthcoming SU team project with a Google.org employee who also had a machine learning PhD. “She said that she has a friend who is blind and a problem that still isn’t solved yet is getting from A to B,” recalls Cheng.
“We also had the CTO of IBM Watson come and give us a presentation and we remembered some of the demos given to us about how it can do semantic descriptions, and how it can also do some pretty good image recognition, so we looked into that — and we looked into how can we combine the two to create a better experience for navigating through the physical world for the visually impaired,” adds Rizzoli.
Where do they hope to be with Aipoly in a year’s time? Their aim is to graduate from an MVP to an app that’s in the hands of the visually impaired “across the world”, says Rizzoli, with an algorithm that “recognizes all the objects that they need to navigate their life”.
“We hope that to be the main asset of our business and to use that algorithm that not only recognizes objects that can be products but objects that have to do with navigation, to help not only the visually impaired but everyone — from humans to machines — in navigating and recognizing the world. That’s the core mission of Aipoly,” he adds.