There are barely any mountain bikers, climbers, skydivers or skiers left who don’t have a GoPro camera attached to their helmet. Nobody really wants to sit through an hour of video of you heading up and down the slopes, however. You could just speed those videos up, but then they become completely unwatchable.
Thanks to a new Microsoft Research project, however, you may soon be able to turn those long boring first-person videos into really smooth hyperlapse sequences that run at 10x the speed of the original video but don’t make you want to throw up because of the camera shake.
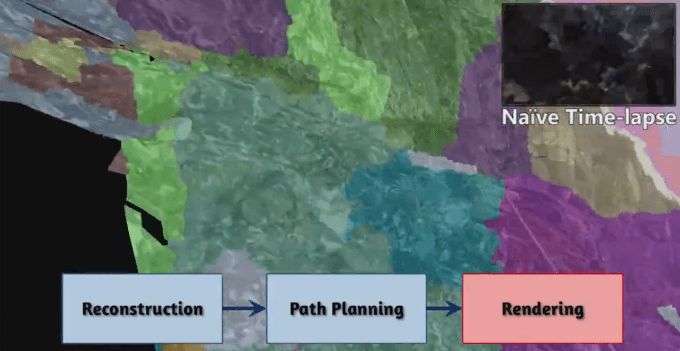 Developed by Johannes Kopf, Michael Cohen and Richard Szeliski, the new project — which the team says could soon become available as a Windows app — takes your typical first-person video and then runs it through its algorithms to construct a new, smoother camera path.
Developed by Johannes Kopf, Michael Cohen and Richard Szeliski, the new project — which the team says could soon become available as a Windows app — takes your typical first-person video and then runs it through its algorithms to construct a new, smoother camera path.
This is much more than just some fancy version of the warp stabilizer you may be familiar with from other video editing tools, however. Microsoft’s project also reconstructs the scene itself by creating a depth map based on the video input. With this data, the algorithm can then stitch together an image from a viewpoint that’s slightly different from the original perspective to keep the video as smooth as possible.
 The software takes information from multiple input frames to create these new frames. That feels a bit similar to what Microsoft is doing with Photosynth and maybe that’s no surprise because Kopf and Szeliski also worked on that project.
The software takes information from multiple input frames to create these new frames. That feels a bit similar to what Microsoft is doing with Photosynth and maybe that’s no surprise because Kopf and Szeliski also worked on that project.
When you watch the new videos closely, you can see that the algorithm doesn’t always work perfectly (shapes and objects sometimes appear rather suddenly — similar to what you expect from older 3D video games), but compared to this, the final video is always much more watchable.
The team is presenting its progress at the SIGGRAPH conference in Vancouver, Canada this week.
Here is a more detailed video that explains how the new videos are computed (and a paper that goes into even more detail):