
Today, Identified has unveiled its patent-pending, artificial intelligence technology called “SYMAN,” which aims to organize the masses of disparate, incoherent professional data that lives in our social media profiles in order to identify new insights into the job market. Essentially, Identified co-founders Brendan Wallace and Adeyemi Ajao tell us, SYMAN is an attempt to provide a solution to a problem many social media companies have struggled with for years: Unstructured, disorganized and inconsistent data.
In November 2011, Identified emerged out of public beta on a mission to create a better professional job search engine. Built on top of Facebook data, Identified set out to nibble at LinkedIn’s lead in this space by giving both job seekers and companies a better way to connect — and find talent. To do that, the startup offered a product that it promised would become something akin to the “Google Page Rank for people,” assigning a numerical rank (out of 100) to professionals and companies based on their education, career path, social footprint and more — a la Klout.
By the following summer, Identified had attracted three million active users and had imported 10 million profiles from Facebook, which it used to secure a sizable $21 million series B financing round, led by VantagePoint Capital and Capricorn Investment Group, along with participation from Tim Draper, Innovation Endeavors, Chamath Palihapitiya and more. After this early buzz and validation subsided, however, Identified was met with the challenge of having to convince and incentivize the younger generations to claim and fill out their Facebook-derived profiles on its platform — not such an easy task when so many people already have a litany of online profiles to manage.
But doing so is critical for Identified, because without users claiming their profiles and adding more data, an Identified profile isn’t worth much more than any other. Plus, it means the company has fewer data points with which to work when trying to assign an accurate score or effectively tracking a user’s career progress. As such, Identified has spent the last nine months in relative silence, hiring data scientists and designers and building out its team in an attempt to create technology that would set it apart from the field and enable it to begin monetizing.
 For the enterprise, startups (or really any company) to make use of social media data in a way that’s actually valuable and contains actionable insight, that unstructured, messy social data needs to be cleaned and structured in a way that makes sense. For example, “dirty data,” as the co-founders call it, makes it difficult to deliver high-quality search or analytics products — part of the reason why Facebook’s GraphSearch hasn’t yet seen substantive adoption from recruiters and partly explains why LinkedIn’s career map didn’t take off, respectively.
For the enterprise, startups (or really any company) to make use of social media data in a way that’s actually valuable and contains actionable insight, that unstructured, messy social data needs to be cleaned and structured in a way that makes sense. For example, “dirty data,” as the co-founders call it, makes it difficult to deliver high-quality search or analytics products — part of the reason why Facebook’s GraphSearch hasn’t yet seen substantive adoption from recruiters and partly explains why LinkedIn’s career map didn’t take off, respectively.
By putting social media data in a clean, organized format, companies can more effectively ingest this data to power recruiting, human capital management, CRM, marketing and a host of other enterprise products. To help solve this problem, Identified partnered with a team of former LinkedIn data scientists to develop SYMAN. Inspired by some of the early work that LinkedIn did on its professional dataset, the startup is applying that methodology to a much larger trove of professional data: Facebook.
While one might not think of Facebook as being the go-to site for professional information (especially as many are keen to keep their social and professional profiles separate), with over one billion people on the social network, there’s still an enormous amount of professional data to be gleaned from its profiles. Facebook’s dataset is, as one might expect, more than five-times the size of that of LinkedIn, far less structured and much less complete.
That’s all well and good, but how does it work? Without revealing all the nuts and bolts behind the patent-pending technology, SYMAN’s data architecture enables a machine to draw inferences about the meaning of a particular data entry based on context in much the same way the human brain does. In other words, knowing that someone wrote “Analyst” as their job title on Facebook might not be of much help when making predictions about their ideal professional career. However, by considering complementary and related data, like their education, company and friend, SYMAN can infer that the person is in fact a “Systems Analyst” at Cloudera.
Comparing biographical, professional and educational data against the career path of a “typical” systems analyst, Identified can now predict that Palantir, for example, might be the best (and most logical) next step in the career path for that particular analyst. The data schema and learning algorithms behind SYMAN, Wallace says, are inspired by pioneering neuroscience research proposed by Jeff Hawkins (the founder of Palm and Handspring) and Ray Kurzweil, who recently joined Google to develop a similar technology and apply it to pattern recognition.
 Identified has also developed SYMAN to create and inform a new product, which is currently in beta and being tested by 30 or so clients, called Identified Recruit. Just as LinkedIn used its enterprise recruiting tools to begin monetizing its dataset, the startup hopes to use its new product to enable recruiters to more easily and effectively search and identify candidates based on professional information culled from Facebook. In other words, Identified wants to turn Facebook into a candidate database just as LinkedIn has converted its own for similar uses.
Identified has also developed SYMAN to create and inform a new product, which is currently in beta and being tested by 30 or so clients, called Identified Recruit. Just as LinkedIn used its enterprise recruiting tools to begin monetizing its dataset, the startup hopes to use its new product to enable recruiters to more easily and effectively search and identify candidates based on professional information culled from Facebook. In other words, Identified wants to turn Facebook into a candidate database just as LinkedIn has converted its own for similar uses.
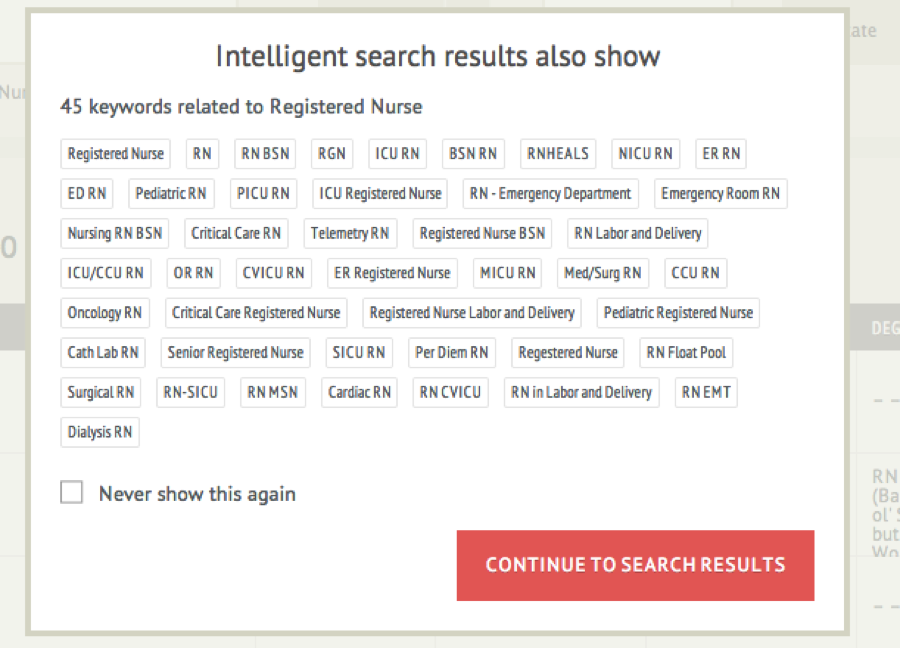
The product is currently being used by enterprise health clients, like Kaiser Permanente for example, to find healthcare candidates who traditionally have shied away from building LinkedIn profiles, like nurses and patient care professionals, in particular. To give an example of how its new product is being applied in this context, SYMAN was able to find 562 ways in which nurses self-identify on Facebook (how they say “I’m a nurse,” in other words).
The technology then maps these 562 different terms to 15 unique categories or “15 different types of nurses that recruiters are actually looking for,” Wallace explains, enabling recruiters to find more in one search than they would be able to otherwise, using GraphSearch, for example. At present, Identified has only “cleaned” healthcare data via SYMAN, but going forward, the company intends to apply the technology to other industries, like finance, education and life sciences — to name a few on the near-term roadmap.
Moving forward, the co-founders tell us that they’re also keen on integrating other datasets, applying SYMAN not only to Facebook, but to LinkedIn, Twitter, Pinterest, Quora, Github and others. Though this will take some time, one can also see the company using its new tech to develop analytics products for professionals and companies, like, say, products that would them optimize their workforce and view leads, candidates and more in a centralized dashboard.
Also on the roadmap, Wallace says, is the development of an API for a variety of social media sites, which would allow companies to use SYMAN to clean and organize their data, on-demand. Data-cleaning-as-a-service, in other words. The founders also hope that, through its future API, SYMAN could enable companies to monetize their data for enterprise applications in a way they’re currently unable to do, as well as allowing developers and third-parties to build B2B tools, apps and tools on top of SYMAN’s technology.
Of course, in the big picture, the applications for SYMAN are just beginning to take root, so it’s still too early to say just how effective and attractive this kind of technology will be to other companies. But, based on where Identified was a year ago, it certainly feels like a step in the right direction, especially if it means to monetize in any significant way. Sure, it’s easy to talk about what could be, making Identified’s future plans for its technology seem like pie-in-the-sky-type conceptualizing at this point.
However, the startup does seem to have assembled a team of experienced data scientists and engineers, and the recent addition of two new board members from well-known recruiting and human capital companies may be a sign that the startup is at least moving in the right direction. To that point: This quarter, Wallace says, the company officially added Jobvite CEO Dan Finnigan and Max Simkoff, the founder and CEO of Evolv, to its board of directors.
As to what he sees as the potential for SYMAN, Simkoff says that he thinks the technology could solve a problem “that plagues big social data and which no other social or professional network has really been able to solve effectively,” and as such, could “uncover powerful insights and relationships buried deep within the Social Web, which have the potential to change how companies pursue talent, manage their workforce, and understand their competition.”
For more, find Identified at home here, more on its recruiting product here and a brief video demo below: