Amazon Web Services unveiled a suite of new features for Amazon EC2 which will help users monitor cloud capacity, scale on demand, and spread incoming traffic across multiple web servers. Amazon originally announced these features last fall, but the applications didn’t enter public beta until today.
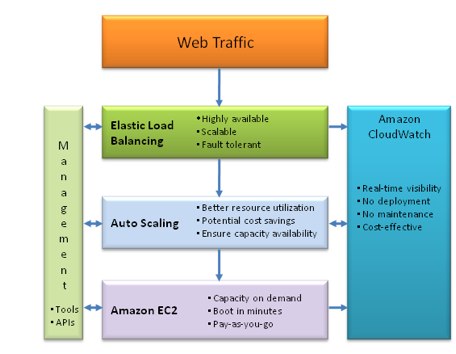
The first feature, Amazon CloudWatch, provides customers with real-time visibility into resource utilization, operational performance, and overall demand patterns—including metrics such as CPU utilization, disk reads and writes, and network traffic. The metrics are rolled-up at one minute intervals and are retained for two weeks.
Amazon’s scaling feature, Auto Scaling, allows you to automatically scale your Amazon EC2 capacity up or down according to metrics you receive from CloudWatch. With Auto Scaling, you can make sure that the number of Amazon EC2 instances you’re using scales up during demand spikes to maintain performance, and scales down automatically during demand lulls to minimize costs.
Elastic Load Balancing will automatically distribute incoming application traffic across multiple Amazon EC2 instances. The feature will detect problem instances within a group and will automatically reroutes traffic to working instances until the unhealthy instances have been restored. Users can also implement “Health Checks” to figure out the viability of each instance via pings and URL fetches.
The new features, which were added due to customer demand, are aimed to give EC2 customers greater visibility of the cloud while still being able to scale on demand, direct traffic and manage overloads easily. It appears that these features would be fairly useful for customers and definitely makes AWS a more powerful cloud computing platform.