Wolfram Alpha is an early primitive. The new search engine that everybody is gushing over and that even Sergey Brin is keeping an eye on, is set to launch on Monday and may soft-launch as early as later today. If you can’t wait that long the first 50 TechCrunch readers to send an email to techcrunchpreview@wolfram.com will get invited to a fully-functioning preview. (Update: invites are way gone). Or check out this screencast, which goes through some examples of what Wolfram Alpha can do.
I’ve been putting Wolfram Alpha through the paces for the past few days and I come away impressed, but not super-impressed. Wolfram Alpha is obviously at a very early stage of development (hence the “alpha” in the name), and it does show a lot of promise. It is certainly not going to be another Cuil, the once-stealth search engine which fell flat on its face at launch. But given all the hype that is surrounding Wolfram Alpha’s launch, the already-brimming rivalry with Google, and the fact that it just bought a supercomputer to help handle its expected load, it needs to be evaluated seriously and without a handicap. When the company states on its blog that its algorithms “include some of the most sophisticated ever developed” it is helping to set expectations pretty high.
Wolfram Alpha is not a regular search engine. It doesn’t scour the Web for data to return the best results. Rather, it ingests data into its own massive databases so that it can run the information through its own constantly-growing set of algorithms to “compute” the answers. These algorithms are based on computer scientist Stephen Wolfram’s Mathematicasoftware. When it does come up with an answer, it can be brilliant. Scientists, engineers, and math geeks are going to love Wolfram Alpha. It can do calculus, regression analysis, compute orbital paths and fluid dynamics, and call up detailed information about specific genes. But too often it doesn’t have the best answers for basic questions and searches.
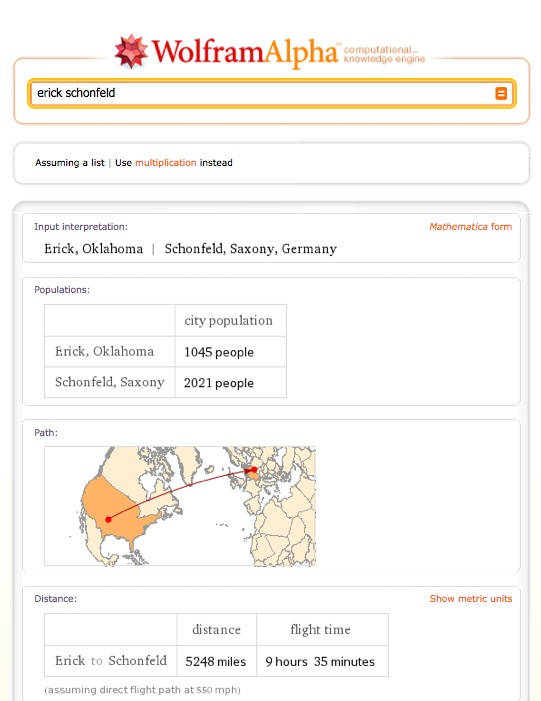
For instance, it doesn’t do so well with searches for people who are not famous. I tried a vanity search of my name, for instance, and it came back with the distance between Erick, Oklahoma and the town of Schonfeld in Saxony, Germany (5,248 miles).
A search for “techcrunch” came up with nothing. Company names work better for publicly traded companies. You get the stock price and financial data when you search for “Google.” A search for Facebook turns up Alexa data about the site such as pageviews and daily visitors (Alexa is not always the most accurate source for this sort of Web data, however). When I asked, “How much is Facebook worth?” it was comically flummoxed, responding: “Wolfram Alpha isn’t sure what to do with your input.” To be fair, nobody (person or computer) in the world knows the answer to that question.

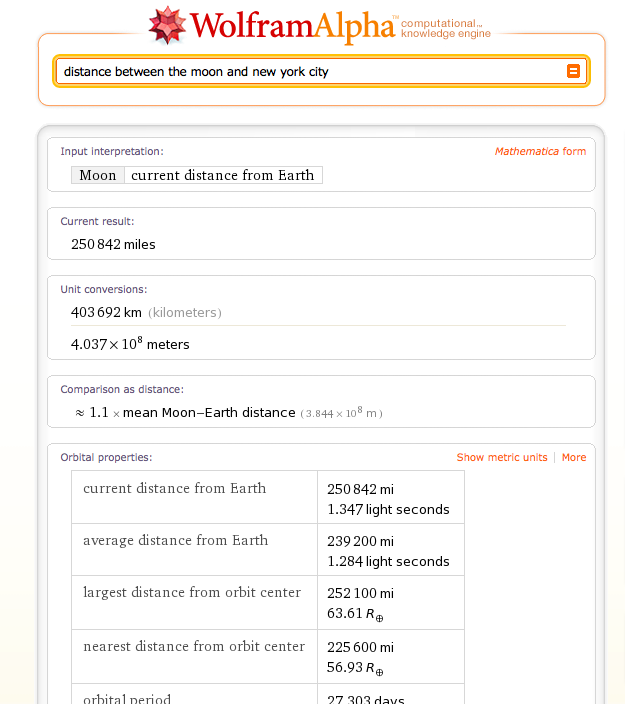
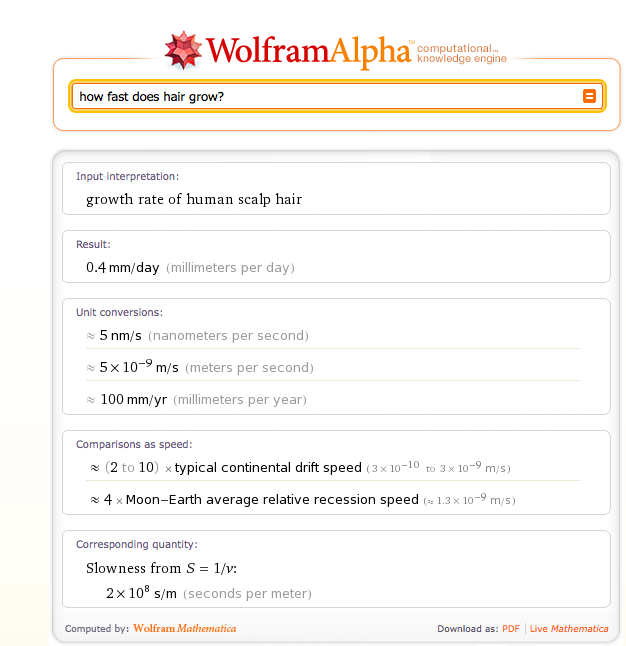
How about when it does have an answer? I asked it “How fast does hair grow?” It came back with “0.4 mm/day.” It also gave me the answer in nanometers per second (5) and millimeters per year (100). It also knows the “distance between the moon and New York City” (250,842 miles right now), as well as the “Answer to Life, the Universe, and everything,” which is “42” (as anyone who has read the Hitchhiker’s Guide to the Galaxy will tell you, as will Google).
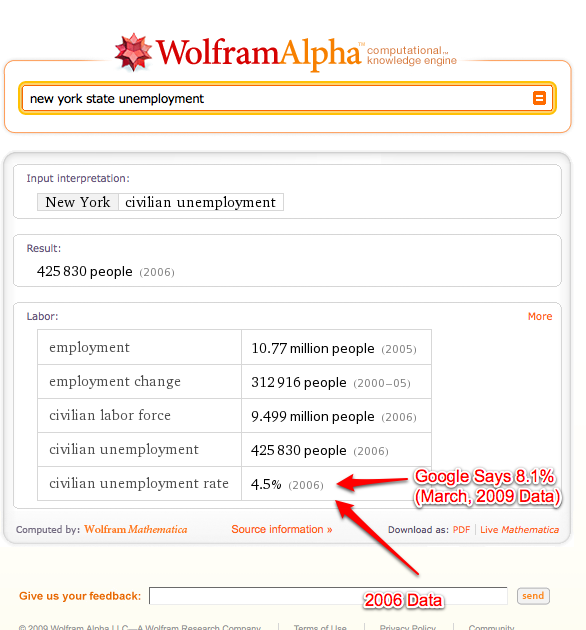
Even when Wolfram does have an answer, it is not always the best one. For instance, a search for “new york state unemployment” brings up a 4.5 percent unemployment rate from 2006 (see screen shot above). That answer is completely useless if you want to know the current unemployment rate in New York State, which is 8.1 percent and which turns up as the first result on Google. I chose this search because Google recently added some basic structured data to searches for U.S. unemployment and population. Google pulls these results directly from the Bureau of Labor Statistics, whereas Wolfram can only compute information based on the data it has already ingested.
When I do a search for “New York versus California,” Wolfram Alpha comes up with a wealth of trivia, including population, state capitals, the dates they joined the Union, their locations highlighted on a map, land area, highest points, lowest points, number of households, number of businesses, median household income, and more. All of this information is great, but is it the best information? Much of the data is from 2002. The population numbers are from 2006. Search for “New York state population” on Google and you get a July, 2008 estimate pulled straight from the U.S. Census Bureau.
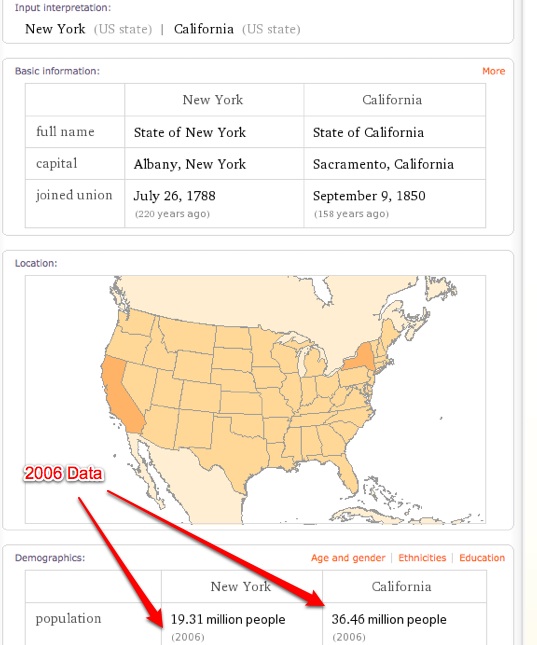
Of course, Google doesn’t provide all of the other contextual data in one convenient search result, but its answer for that one variable is better. All Wolfram has to do, though, to beat Google is update its data, right? That is easy enough. It is already an amazing resource and it will only get better over time. But there is a question of scale and approach here. Wolfram needs supercomputers to “compute” its answers. It is not searching for answers that are already out there. Supercomputers are expensive and generally don’t scale cost-effectively. Beyond that is the issue of whether Wolfram can ingest enough data fast enough to always be up to date, versus finding the best, most current answer to any query on the Web. To put it another way, can Wolfram Alpha ever become smarter than the Web? That simply does not compute.
Finally, it is not as though Web isn’t evolving as well. Wolfram needs to store all of the data it sifts through in its own databases because that is how it imposes structure on the data. The Web is messy and unstructured. Yet there is a general movement afoot to impose structure on the data found across the Web. Everyone from semantic search startups to Google itself is making the Web more computable by categorizing the information on it in a way that computers can understand and manipulate more easily. Of course, to the extent that happens, Wolfram Alpha can take advantage of it as well.
In search, whoever can come up with the best answer wins. As promising as it is, that isn’t Wolfram Alpha yet.