![]() Google may be good at many things, but people search is not one of them. For that you’ll have to use a more specialized search engine. Spock and Wink (merged with Reunion.com) are the people-search destinations most TechCrunch readers could probably name off the top of their head. However, slowly but surely—and mostly, very quietly—a new player has been making serious headway in this search vertical, and it’s name is Pipl.com.
Google may be good at many things, but people search is not one of them. For that you’ll have to use a more specialized search engine. Spock and Wink (merged with Reunion.com) are the people-search destinations most TechCrunch readers could probably name off the top of their head. However, slowly but surely—and mostly, very quietly—a new player has been making serious headway in this search vertical, and it’s name is Pipl.com.
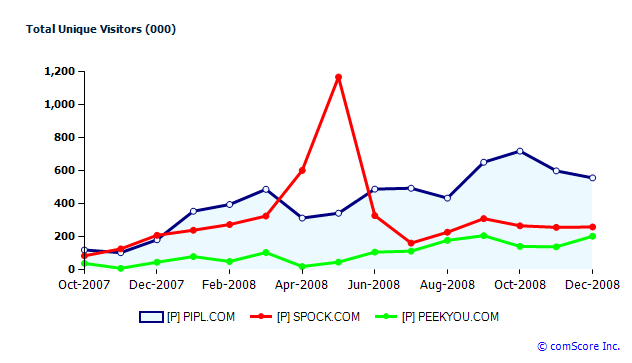
Going by ComScore’s December numbers, Pipl is leading in the US with 557K unique users to Spock’s 260K, but is trailing internationally with 1.35M uniques to Spock’s 2.38M. How has Pipl pulled this off? Matthew Hertz, the company CEO, tells me it’s mostly word-of-mouth. It’s a simple answer but it rings true. Just take it out for a spin and you’ll see why—it’s just good. In fact it’s so good it’ll probably scare some people’s pants off when they see what information it is able to—legally—drudge up.
It produces not only links to all of your profiles on social networks like Facebook, MySpace, and LinkedIn, blog mentions, and photos on Flickr. It finds mentions of your name in public records, including property records, SEC filings, and birth databases. It also finds e-mail addresses and summarizes “quick facts” about the person. For instance, a search for “Roi Carthy” turns up quick facts like these:
Roi Carthy is an Israeli-based entrepreneur and startup consultant…
Editor’s note: Roi Carthy is currently writing for TechCrunch…
Unlike most search engines, Pipl crawls the Deep Web. I’ll explain. A general purpose search engine typically crawls the Web by following links to URLs found in other pages. By contrast, the Deep Web is made up of pages that no other pages link to. Dynamic pages are a good example of these sorts of pages. This means that if an engine wants to index pages located in Deep Web repositories it has to “guess” possible URLs. Just how big is the Deep Web? No one really knows but it’s generally accepted that it is vastly greater (orders of magnitude greater) than the Surface Web—the pages which are easily indexed by search engines.
 The folks at Pipl were hesitant to discuss their “secret sauce” with me, so their explanations were on the vague side but here it is in broad strokes: First, Pipl’s crawlers hunt out Deep Web sources and URLs. Special algorithms they developed then perform the “guesswork” of possible inputs. The ensuing pages are then parsed for various types of data and images (Pipl even augments with meta data that appears elsewhere). Finally, using advanced language analysis and ranking, Pipl floats the most relevant portions of information about an individual. Remember, all of this is very tricky because in the Deep Web there is no real way to rate a web page based on its importance, for the simple fact that no other page is linking to it.
The folks at Pipl were hesitant to discuss their “secret sauce” with me, so their explanations were on the vague side but here it is in broad strokes: First, Pipl’s crawlers hunt out Deep Web sources and URLs. Special algorithms they developed then perform the “guesswork” of possible inputs. The ensuing pages are then parsed for various types of data and images (Pipl even augments with meta data that appears elsewhere). Finally, using advanced language analysis and ranking, Pipl floats the most relevant portions of information about an individual. Remember, all of this is very tricky because in the Deep Web there is no real way to rate a web page based on its importance, for the simple fact that no other page is linking to it.
Obviously, Pipl is designed for people search by name, but it also just debuted the ability to search emails, usernames and by reverse phone number lookup. The results page is designed as a “one page report” that categorizes information in an easy to read manner. Results are displayed based on accuracy, relevance and importance, particularly useful for results for common names (“John Smith”).
Pipl’s business model is pretty straight forward: Sponsored links and results, all in the form of text ads, displayed on the results pages—there are no banners, keeping the look and feel clean. Most if not all ads are linked to background-report providers, which are far more relevant to US users than the international ones, but hey, revenue is revenue.
So next time you want to search for your former high school sweetheart or a long lost relative, try Pipl, it seems like the best place to start.