Sometime today, StumbleUpon will register its five millionth user. (At the time of this writing, it is at 4,994,826 registered users). That number is kind of meaningless, though, because it counts anyone who has ever registered for the Website-rating and discovery service, and who may no longer use it. StumbleUpon, which is part of eBay, does not disclose how many active users it has.
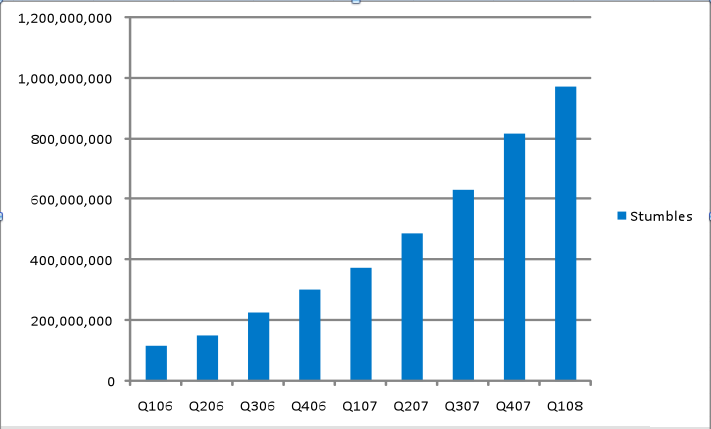
But it did provide me with the nifty little graph above which shows how many times users actually “stumble” something on the Web. (When you like a site or a video you can stumble it by giving it a thumbs up—the more stumbles a page gets, the higher it ranks when others are looking for similar pages). The service is about to collect its five billionth stumble within the next 30 days. Users have already stumbled more than one billion times so far this year. Stumbling activity was up 160 percent during the first quarter of 2008, compared to the same period in 2007 (with 974 million stumbles versus 375 million).
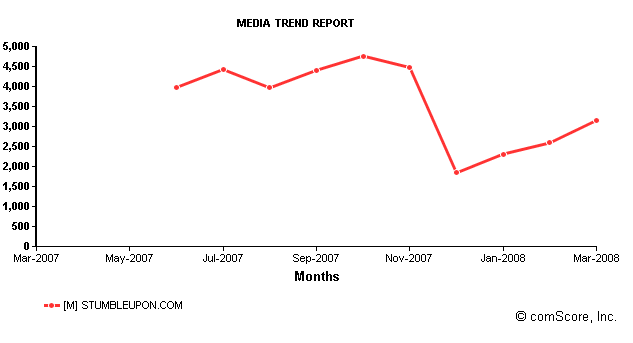
Meanwhile, traffic to the site has been steadily climbing back since taking a huge dive last fall. According to comScore, unique visitors worldwide dropped from 4.8 million last October to 1.8 million in December, but came back up to 3.2 million in March. Many active users never go to the site, and just stumble from their browser toolbar. But as the quality of StumbleUpon’s user-selected index improves, it should attract more casual visitors to its site.
Most people think of StumbleUpon as a socially-powered discovery engine rather than a search engine, but personal discovery and search may be colliding. During a recent speech at the Next Web conference, StumbleUpon founder Garrett Camp noted:
Personalized search is just getting started. I think personalized crawling will start too. Crawlers now are trying to create the biggest map of the web, but implicit filtering and intelligent agents—that is where search and discovery will meet. My query log isn’t actually representative of what I want on the Web.
I like that idea of a personalized Web crawler that indexes only the part of the Web deemed to be most relevant to you and people you know or who share the same interests. Stumbleupon already identifies other users related to you who are drawn to similar Websites, and is building a general index of high-quality sites. The more stumbles it collects, the better its index, and the easier it will be to personalize that down the road. With the number of stumbles rapidly accelerating, the next five billion should take only about another year to gather.