![]() Every media company on the planet knows that its articles, songs, photos, and videos are being copied and spread willy-nilly across the Web, but they don’t have a clue what to do about it. They are not even sure what to do about all of their stuff that is just on YouTube (should they let Google monitor itself or create some vague industry guidelines and hope that every site follows them?). A startup called Attributor in Redwood City, Calif. says it can monitor the Web for copied content no matter where it may be, help publishers and media companies track it all, and help them decide what to do about it.
Every media company on the planet knows that its articles, songs, photos, and videos are being copied and spread willy-nilly across the Web, but they don’t have a clue what to do about it. They are not even sure what to do about all of their stuff that is just on YouTube (should they let Google monitor itself or create some vague industry guidelines and hope that every site follows them?). A startup called Attributor in Redwood City, Calif. says it can monitor the Web for copied content no matter where it may be, help publishers and media companies track it all, and help them decide what to do about it.
Attributor was founded in 2005 and has raised $10 million from Sigma Partners, Selby Ventures, Draper Richards, First Round Capital and Amicus. The enterprise version of its service launches today, although it has been testing it with Reuters and AP for about six months. The enterprise service will cost anywhere from tens of thousands to hundreds of thousands of dollars per year (a more limited self-serve version for bloggers and smaller publishers could cost as little as $6 or $7 per month, and will launch in 2008). CEO Jim Brock gave me a demo of Attributor last week in the lobby of the Waldorf Astoria.
Attributor is already indexing 100 million Web pages a day (15 billion total so far), but it is not a keyword index. It looks for bigger blocks of content. Right now, it can handle only text. Images are in beta. And video matching will go into beta early next year. If you are a publisher that is a customer of Attributor, it ingests all your content and comes up with matches. Attributor splits up the world between sites that exhibit extensive copying (more than half of an article, for instance) and just some copying. It shows which sites have linked back to the original source and which have not. “Often, that’s all they want—a link,” says Brock. Below is a typical dashboard view of what a customer would see. In this case, the content from People.com is being analyzed (based on its feed). Of the 265,000 matches, 103,000 don’t link back to People.com.
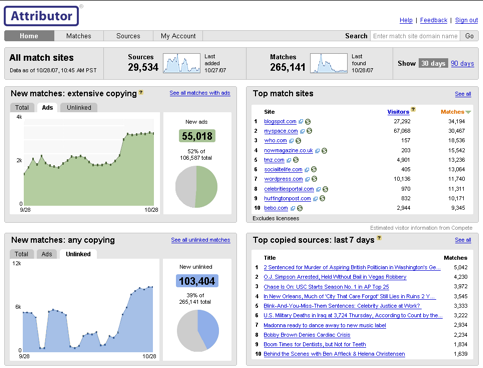
Attributor also shows which sites generate the most traffic, which are supported by ads, and which ad networks are making the most money off of your content across the Web. Of the sites that copy People.com extensively, for instance, 55,000 are supported by ads. “This becomes a billing engine at some level,”says Brock. But rather than go after each offending site, he thinks that Attributor’s data will give media companies leverage against Google and other ad networks. “If I am a big content producer,” reasons Brock, “and I can identify all the pages with Google AdSense, my conversations at that point is with Google.” They could ask Google to ban the offending sites from AdSense or, better yet, to cut them in on some of the advertising revenues associated with their content.
 Ultimately, though, it is all about the links. Links are the currency of the Web. They are the way attributions are made. In most cases, media companies would be better off if they could just get everyone who is copying their stuff to link back to them than by trying to extract licensing fees out of them or suing them. There is a lot less friction in asking for a link, and it doesn’t cost anything to give one out. Yet all of those links can turn into traffic, both directly and by imbuing the original source with higher search karma (i.e. a higher ranking on search engines).
Ultimately, though, it is all about the links. Links are the currency of the Web. They are the way attributions are made. In most cases, media companies would be better off if they could just get everyone who is copying their stuff to link back to them than by trying to extract licensing fees out of them or suing them. There is a lot less friction in asking for a link, and it doesn’t cost anything to give one out. Yet all of those links can turn into traffic, both directly and by imbuing the original source with higher search karma (i.e. a higher ranking on search engines).
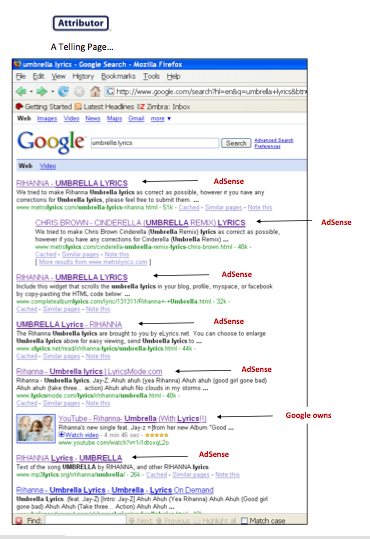
A case in point is what is going on with music lyrcis on the Web. The term “song lyrics” is one of the most popular searches online. In a study just released today (PDF here), Attributor scoured the Web for the lyrics of 14 of the songs at the top of the Billboard charts. It found 1,524 copies, mostly on lyrics sites, social networks, and blogs. The only site that has actually bothered to cut licensing deals with the record labels for these lyrics is Yahoo Music, yet in all Google searches (and even 81 percent of Yahoo searches) other sites outrank Yahoo Music when it comes to finding the lyrics for these 14 songs. Of those sites, 57 percent were supported by ads (mostly AdSense) for ring tones, concert tickets, and the like. A Google search for the lyrics to the Rihanna song Umbrella (pictured above) shows how much AdSense is powering the lyrics Websites.
It’s not just lyrics. In another study evaluating 215 recipes on Epicurious, Attributor found 3.959 copies, 65 percent of which did not link back to Epicurious, and 56 percent of which were ad-supported sites. More than half of the copycat sites ranked higher in searches than Epicurious itself. I asked Attributor to run a search on some of my TechCrunch posts. One reporting some early details of Google’s OpenSocial project (codenamed Maka-Maka) was the 15th most copied post on TechCrunch since June, when Attributor started monitoring our feeds. (This Hulu post was the most copied overall, being copied 572 times).
For the Maka-Maka post, Attributor found 243 copies, with 200 of those taking more than 80 percent of the text. Fewer than 40 percent actually linked back to the original post (you swine!) and 79 percent had ads on the pages. And this is just for one post. I won’t actually link to the offending sites—you know who you are so cough up those links—but here are some screen shots (highlighted portions are copied verbatim from TechCrunch—at least one takes our entire feed, reposts it with AdSense ads, strip out names of the authors, and does not link back to TechCrunch):