 Captchas are well known for keeping automated spammers out and letting humans in. However, ReCaptcha is a rather clever service using them to help digitize books scanned into the Internet Archive as well. It’s a project from the School of Computer Science at Carnegie Mellon.
Captchas are well known for keeping automated spammers out and letting humans in. However, ReCaptcha is a rather clever service using them to help digitize books scanned into the Internet Archive as well. It’s a project from the School of Computer Science at Carnegie Mellon.
The Internet Archive is home to over 200,000 scanned copies of classic books. Some of them are gorgeously crafted, like this children’s book, but fancy styling can make it difficult for computers to translate the books into an indexable digital text. Much like a Mechanical Turk application, ReCaptcha uses humans to translate images of scanned words that a computer couldn’t understand. Notably, Mechanical Turk has been used in the searches for Jim Gray and Steve Fossett.
The scanned words are placed alongside a normal captcha widget so users decode both words at the same time. The word can be run by multiple people to cut down on errors. Catchas also offer the opportunity to convert a lot of words. ReCaptcha’s founders, Luis von Ahn and Ben Maurer estimate that about 60 million CAPTCHAs are solved every day. Assuming that each CAPTCHA takes 10 seconds to solve, it’ this is over 160,000 human hours per day (that’s about 19 years).
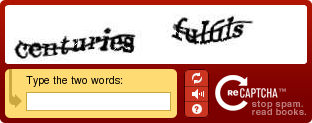
To harness all this time and effort, ReCaptcha is opening their service through captcha widgets and an API. They also have a service for protecting email addresses posted online. You can protect your address by going here and entering it. ReCaptcha then gives you some code to paste your protected address to the web like this, n…@beta.techcrunch.com. To get the address, click the three dots and answer the Captcha.
It’s great to see projects like this harnessing just a bit of our time to solve some important and complex problems.